

在 Stream 篇结中,我们留下了一个问题,下述代码输出的 chunk 是一个什么东西?

通过打印,我们发现 chunk 是 Buffer 对象,其中的元素是16进制的两位数,即0~255的数值。【相关教程推荐:nodejs视频教程、编程教学】

说明在 Stream 中流动的数据就是 Buffer,那下面就让我们来探究一下 Buffer 的真实面目!
? Node 中为什么要引入 Buffer?
最开始的时候 JS 只在浏览器端运行,对于 Unicode 编码的字符串容易处理,但是对于二进制和非 Unicode 编码的字符串处理困难。并且二进制是计算机最底层的数据格式,视频/音频/程序/网络包都是以二进制来存储的。所以 Node 需要引入一个对象来操作二进制,因此 Buffer 诞生了,用于 TCP流/文件系统等操作处理二进制字节。
由于 Buffer 在 Node 中过于常用,所以在 Node 启动的时候已经引入了 Buffer,无需使用 require()
ArrayBuffer
是什么
ArrayBuffer 是内存之中的一段二进制数据,本身不能够操作内存,需要通过TypedArray 对象或者 DataView 来操作。将缓冲区中的数据表示为特定的格式,并通过这些格式来读写缓冲区的内容,其部署了数组接口,可以使用数组的方式来操作数据
TypedArray 视图
最常用的是 TypeArray 视图,用于读写简单类型的 ArrayBuffer,比如 Uint8Array(无符号8位整数)数组视图, Int16Array(16位整数)数组视图
和 Buffer 的关系
NodeJS 中的 Buffer 类其实是 Uint8Array 的实现。
Buffer 结构
Buffer 是一个类似 Array 的对象,但是它主要用于操作字节
模块结构
Buffer 是 JS 和 C++ 结合的模块,性能部分都由 C++ 实现,非性能部分都是 JS 实现的
Buffer 所占用的内存不是由 V8 分配的,属于堆外内存。
对象结构
Buffer 对象类似数组,其元素是16进制的两位数,即0~255的数值
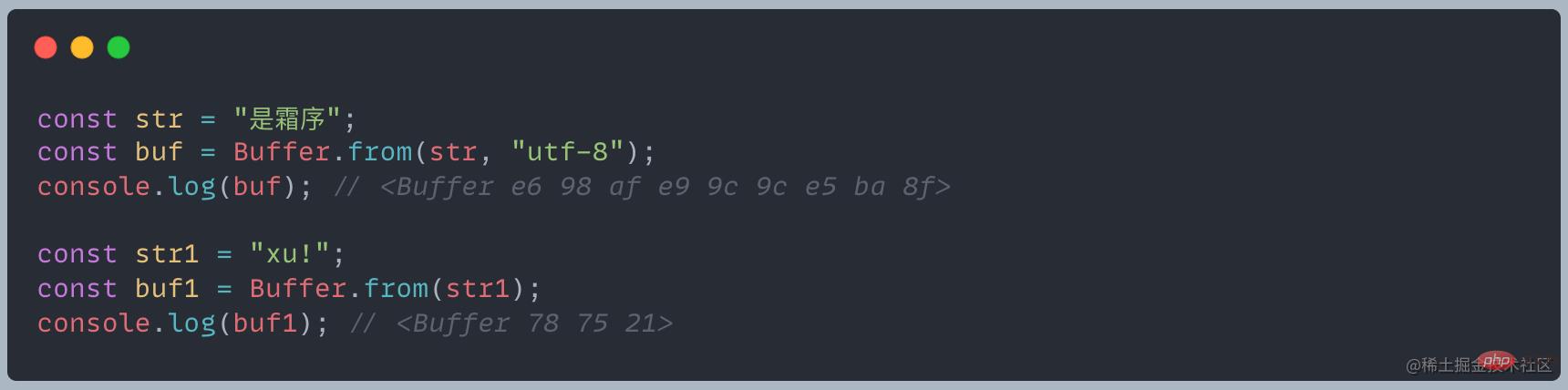
从这个例子能够看出,不同字符在 Buffer 中占据的字节是不一样的,在 UTF-8 编码下,中文占据3个字节,英文和半角标号占用1个字节
? 输入的元素是小数/负数/超出255会发生什么事情?
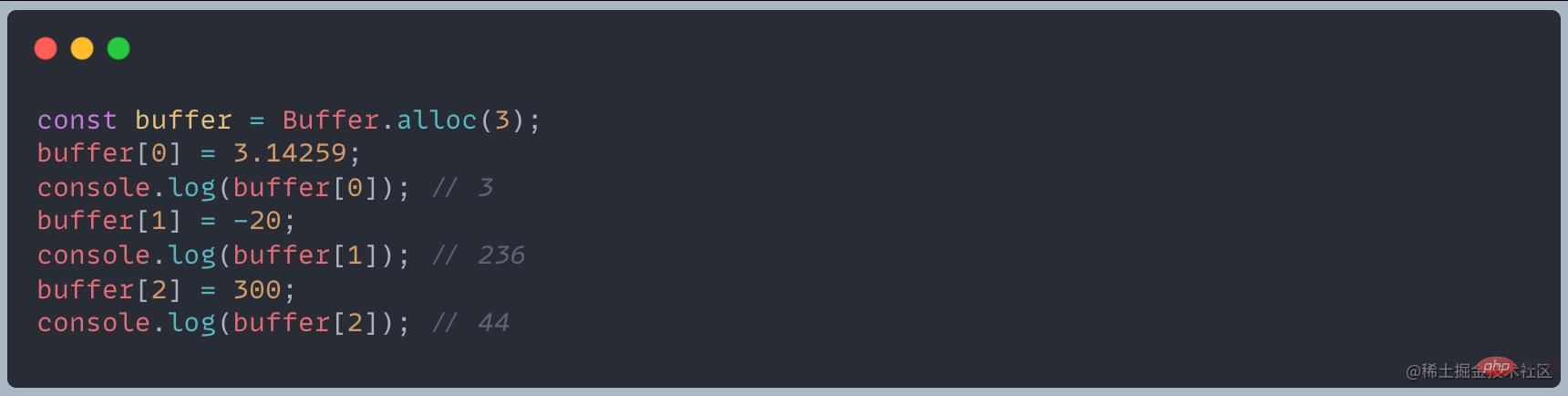
对于上述这种情况,Buffer 的处理为:
- 给元素的赋值小于0, 就将该值逐次加256,直到得到一个0到255之间的整数
- 如果得到的数值大于255,就逐次减256,直到得到0~255区间内的数值
- 如果是小数,只保留整数部分
Buffer 里面为什么展示的是16进制
其实在内存存储的依旧是二进制数,只是 Buffer 在显示这内存数据的时候采用了16进制
大小为2字节的 buffer,一共有16 bit ,比如是00000001 00100011,如果直接这样显示不太方便就转成为了16进制<Buffer 01, 23>
Buffer 的创建
Buffer.alloc 和 Buffer.allocUnsafe
创建固定大小的 buffer
Buffer.alloc(size [, fill [, encoding]])
- size 新 Buffer 的所需长度
- fill 用于预填充新 Buffer 的值。默认值: 0
- encoding 如果 fill 是一个字符串,则这是它的字符编码。默认值: utf8

Buffer.allocUnsafe(size)
分配一个大小为 size 字节的 Buffer,allocUnsafe 执行速度比 alloc 快,我们发现其结果并不像 Buffer.alloc 那样都初始化为 00

当调用 allocUnsafe 时分配的内存段尚未初始化,这样分配内存速度很块,但分配到的内存片段可能包含旧数据。如果在使用的时候不覆盖这些旧数据就可能造成内存泄露,虽然速度快,尽量避免使用
Buffer 模块会预分配一个内部的大小为 Buffer.poolSize 的 Buffer 实例,作为快速分配的内存池,用于使用 allocUnsafe 创建新的 Buffer 实例
Buffer.from
根据内容直接创建Buffer
- Buffer.from(string [, encoding])
- Buffer.from(array)
- Buffer.from(buffer)

Buffer.allocUnsafe 的内存机制
为了高效使用申请来的内存,Node.js 采用了 slab 机制进行预先申请、事后分配,是一种动态的管理机制
使用 Buffer.alloc(size) 传入一个指定的 size 就会申请一块固定大小的内存区域,slab 具有如下三种状态
- full: 完全分配状态
- partial:部分分配状态
- empty:没有被分配状态
Node.js 使用8 KB 为界限来区分是小对象还是大对象

Buffer 在创建的时候大小就已经被确定了且无法调整!
分配小对象
如果分配的对象小于 8KB,Node 会按着小对象的方式来进行分配
Buffer 的分配过程中主要使用一个局部变量 pool 作为中间处理对象,处于分配状态的 slab 单元都指向它。以下是分配一个全新的 slab 单元的操作,它将会新申请的 SlowBuffer 对象指向它
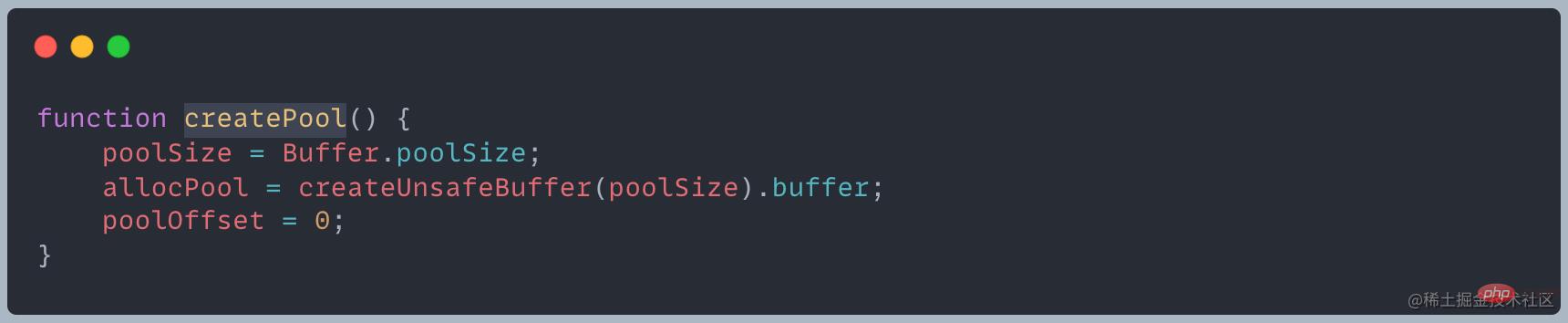
一个 slab 单元
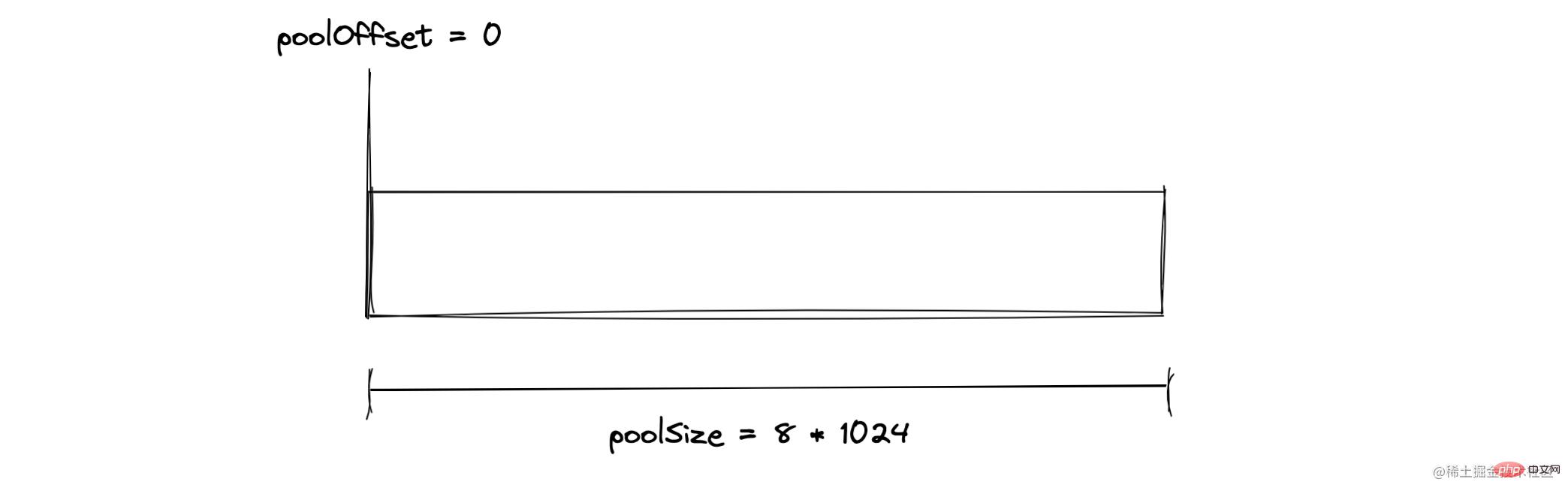
分配一个 2KB 大小的 Buffer
创建一个 2KB 的 buffer后,一个 slab 单元内存如下:
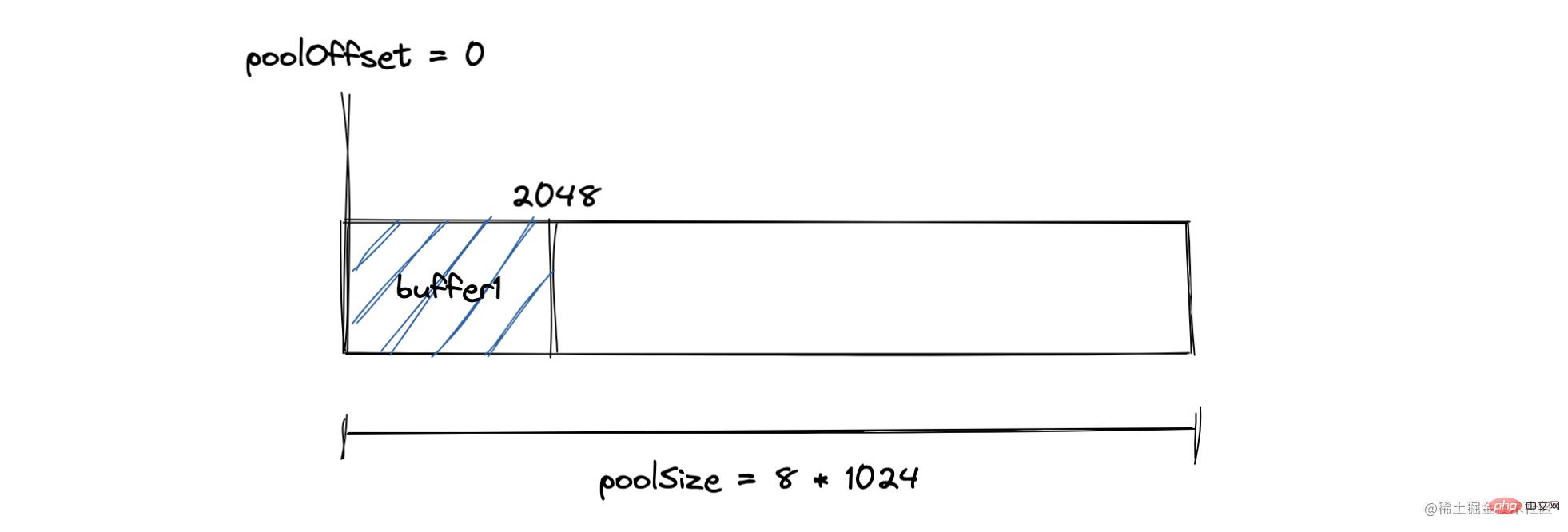
这个分配过程是由 allocate 方法完成
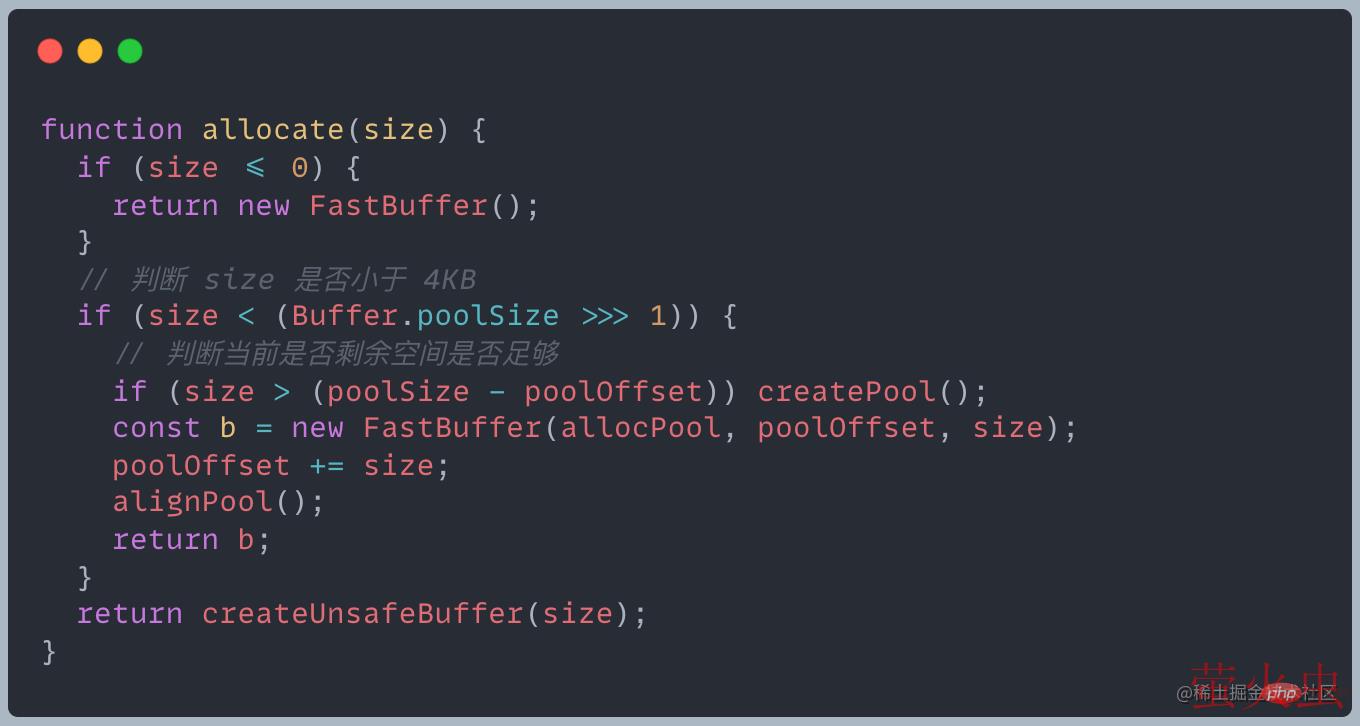
当我们创建了一个 2KB 的 buffer 之后,当前 slab 状态为 partial
再次创建 buffer 的时候,会去判断当前 slab 剩余空间是否足够。如果足够,使用剩余空间,并更新 slab 的分配状态
如果 slab 空间不够,就会构建新的 slab,原 slab 中剩余的空间造成浪费
分配大对象
如果有超过 8KB 的 buffer,直接会走到 creatUnsafeBuffer 函数,分配一个 slab 单元,这个 slab 单元将会被这个大 Buffer 对象独占
allocate 分配机制如图
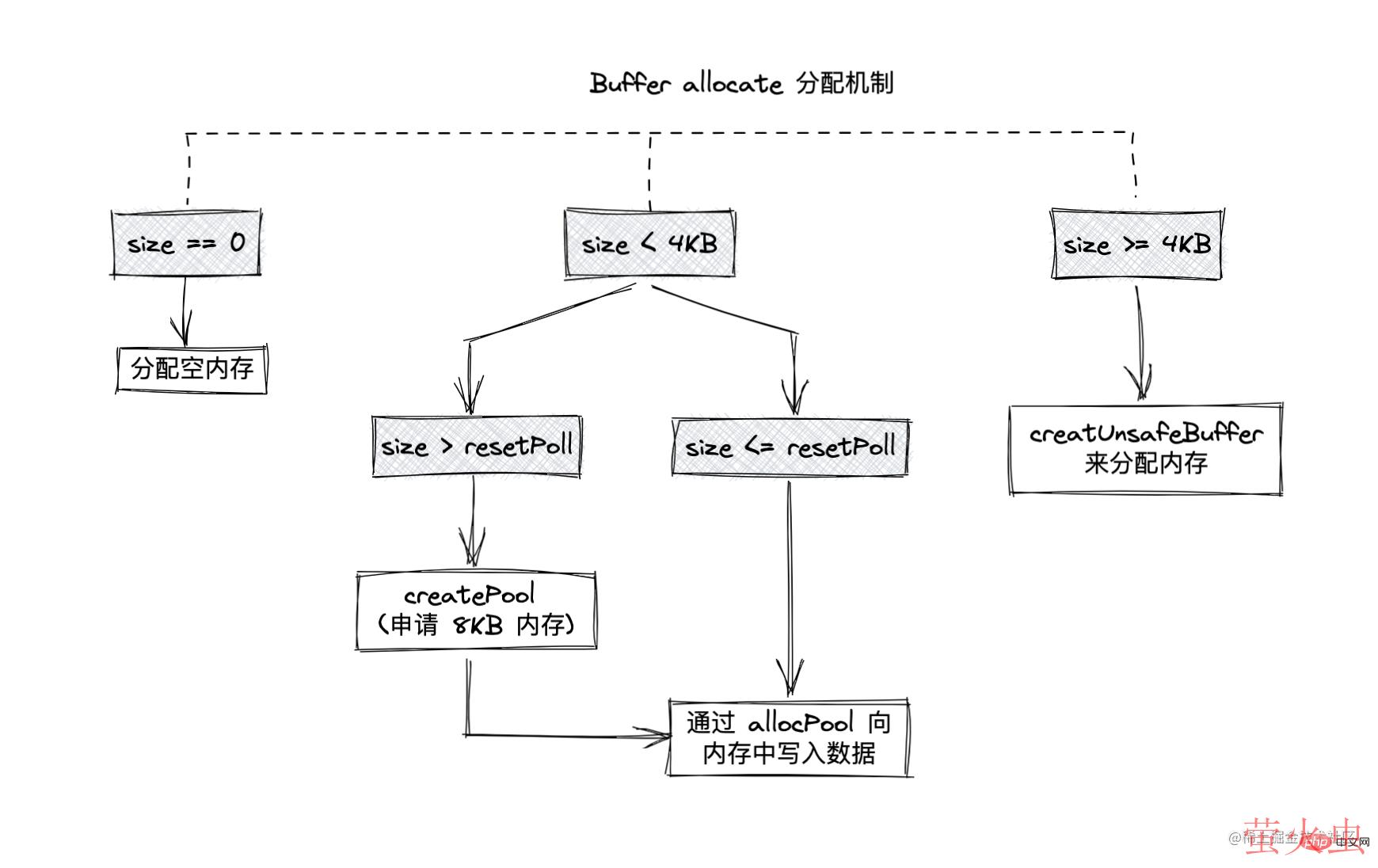
Buffer 的内存分配机制

Buffer 和字符编码
通过使用字符编码,可实现 Buffer 实例与 JavaScript 字符串之间的相互转换
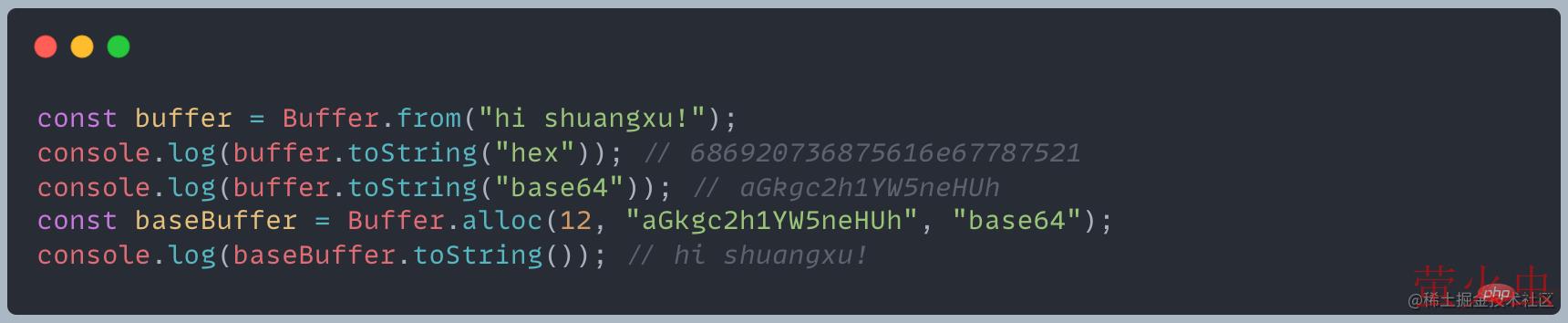
Node 中目前支持 utf8、ucs2、utf16le、latin1、ascii、base64、hex、base64Url 八种编码方式,具体实现

针对于每一种不同的编码方案都会用实现一系列 api,返回会有不同的结果,Node.js 会根据传入的 encoding 来返回不同的对象
Buffer 和字符串的转换
字符串转 Buffer
主要通过上述讲的 Buffer.from 方法,默认的 encoding 方式为 utf-8
Buffer 转字符串

? 为什么会出现乱码呢?如何解决这个问题呢?
按着读取来说,我们每次读取的长度为4,chunk输出如下

对于data += chunk等价于data = data.toString + chunk.toString
由于一个中文占据三个字节,第一个 chunk 中的第四个字节会显示乱码,第二个 chunk 的第一第二个字节也无法形成文字等等,所以会展示乱码问题
更多node相关知识,请访问:nodejs 教程!
以上就是深入了解Node中的Buffer的详细内容,转载自php中文网


发表评论 取消回复