
基于无阻塞、事件驱动建立的Node服务,具有内存消耗低的优点,非常适合处理海量的网络请求。在海量请求的前提下,就需要考虑“内存控制”的相关问题了。

1. V8的垃圾回收机制与内存限制
Js由垃圾回收机制来进行自动内存管理,开发者不需要像其它语言(c/c++)那样在编写代码的过程中时刻关注内存的分配和释放问题。在浏览器中,垃圾回收机制对应用程序构成性能影响较小,但对于性能敏感的服务器端程序,内存管理的好坏、垃圾回收状况是否优良,都会对服务构成影响。【相关教程推荐:nodejs视频教程、编程教学】
1.1 Node 与 V8
Node是一个构建在Chrome的Js运行时上的平台,V8为Node的Js脚本引擎
1.2 V8的内存限制
在一般的后端语言中,对基本的内存使用没有什么限制,但是在Node中通过Js使用内存时,只能使用部分内存。在这样的限制下,导致Node无法直接操作大内存对象。
造成问题的主要原因在于Node基于V8构建,在Node中使用的Js对象基本上都是通过V8自己的方式来进行分配和管理的。
1.3 V8的对象分配
在V8中,所有的Js对象都是通过堆来进行分配的。
查看v8中内存使用情况

heapTotal 和 heapUsed是V8的堆内存使用情况, 前者是已申请到的堆内存,后者是当前使用的量。
在代码中声明变量并赋值时,所使用对象的内存就分配在堆中。如果已申请的堆空闲内存不够分配新的对象,将继续申请堆内存,直到堆的大小超过V8的限制为止
V8为何要限制堆的大小,表层原因为V8最初为浏览器而设计,不太可能遇到用大量内存的场景。对于网页来说,V8的限制值已经绰绰有余。深层原因是V8的垃圾回收机制的限制。按官方的说法,以1.5G的垃圾回收堆内存为例,v8做一次小的垃圾回收需要50毫秒以上,做一次非增量式的垃圾回收甚至要1秒以上。这是垃圾回收中引起Js线程暂停执行的时间,应用的性能和响应能力都会直线下降。在当时的考虑下直接限制堆内存是一个好的选择。
这个限制是可以放开的,Node在启动的时候,可以传递--max-old-space-size或--max-new-space-size来调整内存限制的大小,一旦生效就不能再动态改变。如:
node --max-old-space-size=1700 test.js // 单位为MB // 或者 node --max-new-space-size=1024 test.js // 单位为KB
1.4 V8的垃圾回收机制
v8用到的各种垃圾回收算法
1.4.1 V8主要的垃圾回收算法
v8的垃圾回收策略主要基于分代式垃圾回收机制。
在实际的应用中,对象的生存周期长短不一。现在的垃圾回收算法中按对象的存活时间将内存的垃圾回收进行不同的分代,对不同分代的内存施以更高效的算法。
v8的内存分代
在v8中,主要将内存分为新生代和老生代两代。新生代中的对象为存活时间较短的对象,老生代中的对象为存活时间较长或常驻内存的对象。
新生代的内存空间 老生代的内存空间 v8堆的整体大小=新生代所用内存空间+老生代的内存空间
v8堆内存的最大值在64位系统下只能使用约1.4GB内存和在32位系统下只能使用约0.7GB内存
Scavenge算法
在分代的基础上,新生代中的对象主要通过Scavenge算法进行垃圾回收。Scavenge具体实现主要采用了Cheney算法。 Cheney算法是一种采用复制的方式实现的垃圾回收算法。将堆内存一分为二,每一部分空间称为semispace。在这两个semispace空间中,只有一个处于使用中,另一个处于闲置状态。处于使用状态的semispace空间称为From空间,处于闲置状态的空间称为To空间。分配对象时,先是在From空间进行分配。当开始进行垃圾回收时,会检查From空间中的存活对象,这些存活对象将被复制到To空间中,而非存活对象占用的空间将会被释放。完成复制后,From空间和To空间的角色发生对换。简而言之,在垃圾回收过程中,就是通过将存活对象在两个semispace空间之间进行复制。 Scavenge的缺点是只能使用堆内存中的一半,这是由划分空间和复制机制所决定的。但Scavenge由于只复制存活的对象,并且对于生命周期短的场景存活对象只占少部分,所以它在时间效率上有优异的表现。 由于Scavenge是典型的牺牲空间换取时间的算法,所以无法大规模地应用到所有的垃圾回收中。但Scavenge非常适合应用在新生代中,因为新生代中对象的生命周期较短,适合这个算法。
 实际使用的堆内存是新生代中的两个semispace空间大小和老生代所用内存大小之和。
实际使用的堆内存是新生代中的两个semispace空间大小和老生代所用内存大小之和。
当一个对象经过多次复制依然存活时,会被认为是生命周期较长的对象,会被移动到老生代中,采用新的算法进行管理。对象从新生代中移动到老生代中的过程称为晋升。
在单纯的Scavenge过程中,From空间中的存活对象会被复制到To空间中去,然后对From空间和To空间进行角色对换(翻转)。但在分代式垃圾回收的前提下,From空间中的存活对象在复制到To空间之前需要进行检查。在一定条件下,需要将存活周期长的对象移动到老生代中,也就是完成对象晋升。
对象晋升的条件主要有两个,一个是对象是否经历过Scavenge回收,一个是To空间的内存占用比超过限制。
在默认情况下,V8的对象分配主要集中在From空间中。对象从From空间中复制到To空间时,会检查它的内存地址来判断这个对象是否已经经历过一次Scavenge回收。如果已经经历过了,会将该对象从From空间复制到老生代空间中,如果没有,则复制到To空间中。晋升流程图如下:
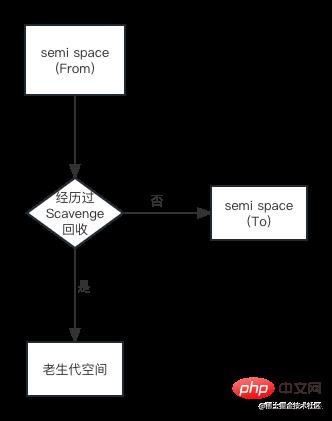
另一个判断条件是To空间的内存占用比。从From空间复制一个对象到To空间时,如果To空间已经使用了25%,则这个对象直接晋升到老生代空间中,晋升流程图如下:
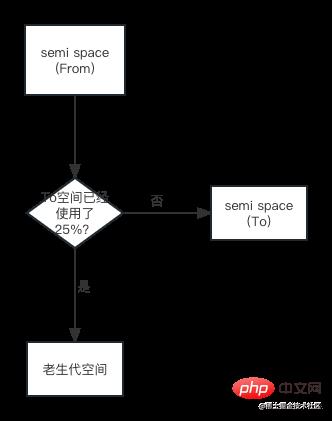
设置25%限制的原因:当这次Scavenge回收完成后,这个To空间将变成From空间,接下来的内存分配将在这个空间中进行。如果占比过高,会影响后续的内存分配。
对象晋升后,将会在老生代空间中作为存活周期较长的对象来对待,接受新的回收算法处理。
Mark-Sweep & Mark-Compact
对于老生代中的对象,由于存活对象占较大比重,如果采用Scavenge的方式有两个问题:一个是存活对象较多,复制存活对象的效率将会很低;另一个问题是浪费一半的空间。为此,v8在老生代中主要采用了Mark-Sweep和Mark-Compact相结合的方式进行垃圾回收。
Mark-Sweep是标记清除的意思,分为标记和清除两个阶段。与Scavenge相比,Mark-Sweep并不将内存空间划分为两半,所以不存在浪费一半空间的行为。与Scavenge复制活着的对象不同,Mark-Sweep在标记阶段遍历堆中的所有对象,并标记活着的对象,在随后的清除阶段中,只清除没有被标记的对象。可以发现,Scavenge中只复制活着的对象,而Mark-Sweep只清理死亡的对象。活对象在新生代中只占较小部分,死对象在老生代中只占较小部分,这是两种回收方式能高效处理的原因。Mark-Sweep在老生代空间中标记后的示意图如下,黑色部分标记为死亡的对象

Mark-Sweep最大的问题是在进行一次标记清除空间后,内存空间会出现不连续的状态。这种内存碎片会对后续的内存分配造成问题,需要分配一个大对象时,这时所有的碎片空间都无法完成此次分配,就会提前触发垃圾回收,而这次回收是不必要的。
Mark-Compact就是为了解决Mark-Sweep的内存碎片问题。Mark-Compact是标记整理的意思,是在Mark-Sweep的基础上演变而来的。差别在于对象在标记为死亡后,在整理的过程中,将活着的对象往一端移动,移动完成后,直接清理掉边界外的内存。完成标记并移动存活对象后的示意图,白色格子为存活对象,深色格子为死亡对象,浅色格子为存活对象移动后留下的空洞。
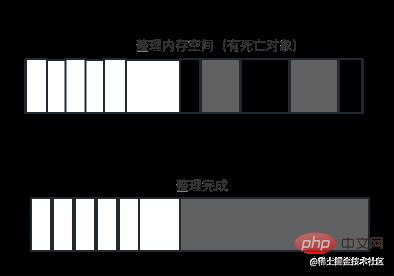
完成移动后,就可以直接清除最右边的存活对象后面的内存区域完成回收。
在V8的回收策略中,Mark-Sweep 和 Mark-Compact 两者是结合使用的。
3种主要垃圾回收算法的简单对比
| 回收算法 | Mark-Sweep | Mark-Compact | Scavenge |
|---|---|---|---|
| 速度 | 中等 | 最慢 | 最快 |
| 空间开销 | 少(有碎片) | 少(无碎片) | 双倍空间(无碎片) |
| 是否移动对象 | 否 | 是 | 是 |
由于Mark-Compact需要移动对象,所以它的执行速度不可能很快,所以在取舍上,v8主要使用Mark-Sweep,在空间不足以对从新生代中晋升过来的对象进行分配时才使用Mark-Compact
Incremental Marking
为了避免出现Js应用逻辑与垃圾回收器看到的不一致情况,垃圾回收的3种基本算法都需要将应用逻辑暂停下来,待执行完垃圾回收后再恢复执行应用逻辑,这种行为称为“全停顿”(stop-the-world).在v8的分代式垃圾回收中,一次小垃圾回收只收集新生代,由于新生代默认配置得较小,且其中存活对象通常较少,所以即便它是全停顿的影响也不大。但v8的老生代通常配置得较大,且存活对象较多,全堆垃圾回收(full垃圾回收)的标记、清理、整理等动作造成的停顿就会比较可怕,需要设法改善
为了降低全堆垃圾回收带来的停顿时间,v8先从标记阶段入手,将原本要一口气停顿完成的动作改为增量标记(incremental marking),也就是拆分为许多小“步进”,每做完一“步进”,就让Js应用逻辑执行一小会儿,垃圾回收与应用逻辑交替执行直到标记阶段完成。下图为:增量标记示意图
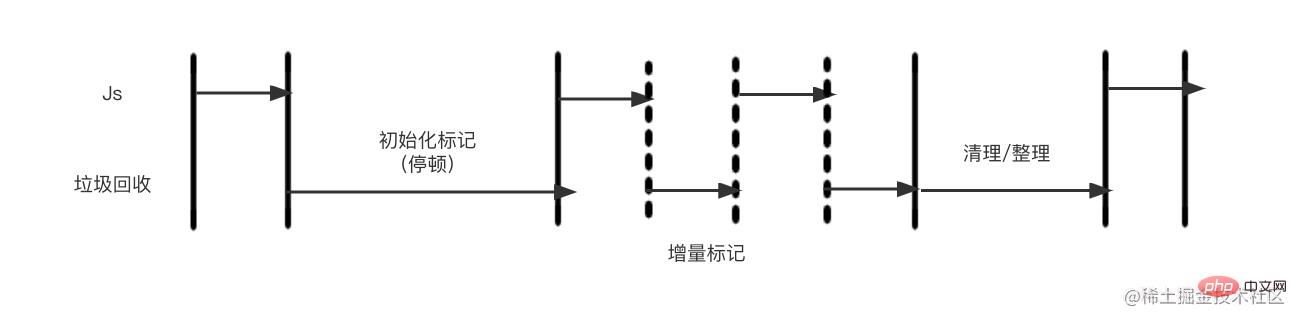
v8在经过增量标记的改进后,垃圾回收的最大停顿时间可以减少到原本的1/6左右。 v8后续还引入了延迟清理(lazy sweeping)与增量式整理(incremental compaction),让清理与整理动作也变成增量式的。同时还计划引入标记与并行清理,进一步利用多核性能降低每次停顿的时间。
1.5 查看垃圾回收的日志
在启动时添加--trace_gc参数。在进行垃圾回收时,将会从标准输出中打印垃圾回收的日志信息。
node --trace_gc -e "var a = [];for (var i = 0; i < 1000000; i++) a.push(new Array(100));" > gc.log

在Node启动时使用--prof参数,可以得到v8执行时的性能分析数据,包含了垃圾回收执行时占用的时间。以下面的代码为例
// test.js
for (var i = 0; i < 1000000; i++) {
var a = {};
}
node --prof test.js会生成一个v8.log日志文件
2. 高效使用内存
如何让垃圾回收机制更高效地工作
2.1 作用域(scope)
在js中能形成作用域的有函数调用、with以及全局作用域
如下代码:
var foo = function(){
var local = {};
}foo()函数在每次被调用时会创建对应的作用域,函数执行结束后,该作用域会被销毁。同时作用域中声明的局部变量分配在该作用域上,随作用域的销毁而销毁。只被局部变量引用的对象存活周期较短。在这个示例中,由于对象非常小,将会被分配在新生代中的From空间中。在作用域释放后,局部变量local失效,其引用的对象将会在下次垃圾回收时被释放
2.1.1 标识符查找
标识符,可以理解为变量名。下面的代码,执行bar()函数时,将会遇到local变量
var bar = function(){
console.log(local);
}js执行时会查找该变量定义在哪里。先查找的是当前作用域,如果在当前作用域无法找到该变量的声明,会向上级的作用域里查找,直到查到为止。
2.1.2作用域链
在下面的代码中
var foo = function(){
var local = 'local var';
var bar = function(){
var local = 'another var';
var baz = function(){
console.log(local)
};
baz()
}
bar()
}
foo()baz()函数中访问local变量时,由于作用域中的变量列表中没有local,所以会向上一个作用域中查找,接着会在bar()函数执行得到的变量列表中找到了一个local变量的定义,于是使用它。尽管在再上一层的作用域中也存在local的定义,但是不会继续查找了。如果查找一个不存在的变量,将会一直沿着作用域链查找到全局作用域,最后抛出未定义错误。
2.1.3 变量的主动释放
如果变量是全局变量(不通过var声明或定义在global变量上),由于全局作用域需要直到进程退出才能释放,此时将导致引用的对象常驻内存(常驻在老生代中)。如果需要释放常驻内存的对象,可以通过delete操作来删除引用关系。或者将变量重新赋值,让旧的对象脱离引用关系。在接下来的老生代内存清除和整理的过程中,会被回收释放。示例代码如下:
global.foo = "I am global object" console.log(global.foo);// => "I am global object" delete global.foo; // 或者重新赋值 global.foo = undefined; console.log(global.foo); // => undefined
虽然delete操作和重新赋值具有相同的效果,但是在V8中通过delete删除对象的属性有可能干扰v8的优化,所以通过赋值方式解除引用更好。
2.2 闭包
作用域链上的对象访问只能向上,外部无法向内部访问。
js实现外部作用域访问内部作用域中变量的方法叫做闭包。得益于高阶函数的特性:函数可以作为参数或者返回值。
var foo = function(){
var bar = function(){
var local = "局部变量";
return function(){
return local;
}
}
var baz = bar()
console.log(baz())
}在bar()函数执行完成后,局部变量local将会随着作用域的销毁而被回收。但是这里返回值是一个匿名函数,且这个函数中具备了访问local的条件。虽然在后续的执行中,在外部作用域中还是无法直接访问local,但是若要访问它,只要通过这个中间函数稍作周转即可。
闭包是js的高级特性,利用它可以产生很多巧妙的效果。它的问题在于,一旦有变量引用这个中间函数,这个中间函数将不会释放,同时也会使原始的作用域不会得到释放,作用域中产生的内存占用也不会得到释放。
无法立即回收的内存有闭包和全局变量引用这两种情况。由于v8的内存限制,要注意此变量是否无限制地增加,会导致老生代中的对象增多。
3.内存指标
会存在一些认为会回收但是却没有被回收的对象,会导致内存占用无限增长。一旦增长达到v8的内存限制,将会得到内存溢出错误,进而导致进程退出。
3.1 查看内存使用情况
process.memoryUsage()可以查看内存使用情况。除此之外,os模块中的totalmem()和freemem()方法也可以查看内存使用情况
3.1.1 查看进程的内存使用
调用process.memoryUsage()可以看到Node进程的内存占用情况
rss是resident set size的缩写,即进程的常驻内存部分。进程的内存总共有几部分,一部分是rss,其余部分在交换区(swap)或者文件系统(filesystem)中。
除了rss外,heapTotal和heapUsed对应的是v8的堆内存信息。heapTotal是堆中总共申请的内存量,heapUsed表示目前堆中使用中的内存量。单位都是字节。示例如下:
var showMem = function () {
var mem = process.memoryUsage()
var format = function (bytes) {
return (bytes / 1024 / 1024).toFixed(2) + 'MB';
}
console.log('Process: heapTotal ' + format(mem.heapTotal) +
' heapUsed ' + format(mem.heapUsed) + ' rss ' + format(mem.rss))
console.log('---------------------')
}
var useMem = function () {
var size = 50 * 1024 * 1024;
var arr = new Array(size);
for (var i = 0; i < size; i++) {
arr[i] = 0
}
return arr
}
var total = []
for (var j = 0; j < 15; j++) {
showMem();
total.push(useMem())
}
showMem();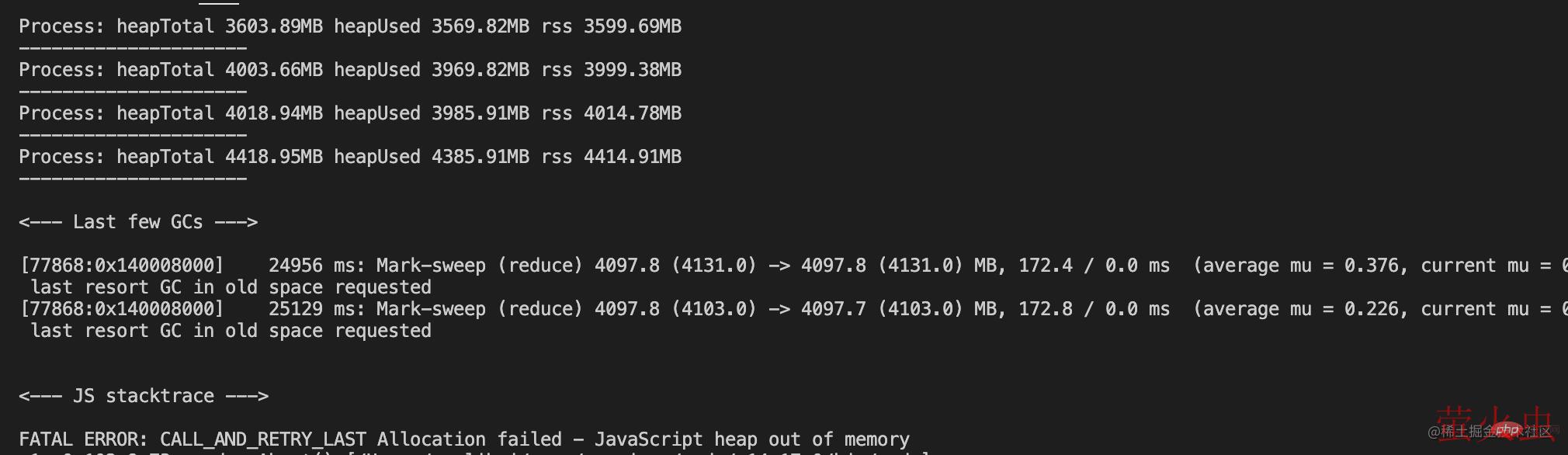
在内存达到最大限制值的时候,无法继续分配内存,然后进程内存溢出了。
3.1.2 查看系统的内存占用
os模块中的totalmem()和freemem()这两个方法用于查看操作系统的内存使用情况,分别返回系统的总内存和闲置内存,以字节为单位

3.2 堆外内存
通过process.memoryUsage()的结果可以看到,堆中的内存用量总是小于进程的常驻内存用量,意味着Node中的内存使用并非都是通过v8进行分配的。将那些不是通过v8分配的内存称为堆外内存
将上面的代码里的Array变为Buffer,将size变大
var useMem = function () {
var size = 200 * 1024 * 1024;
var buffer = Buffer.alloc(size); // new Buffer(size)是旧语法
for (var i = 0; i < size; i++) {
buffer[i] = 0
}
return buffer
}输出结果如下:
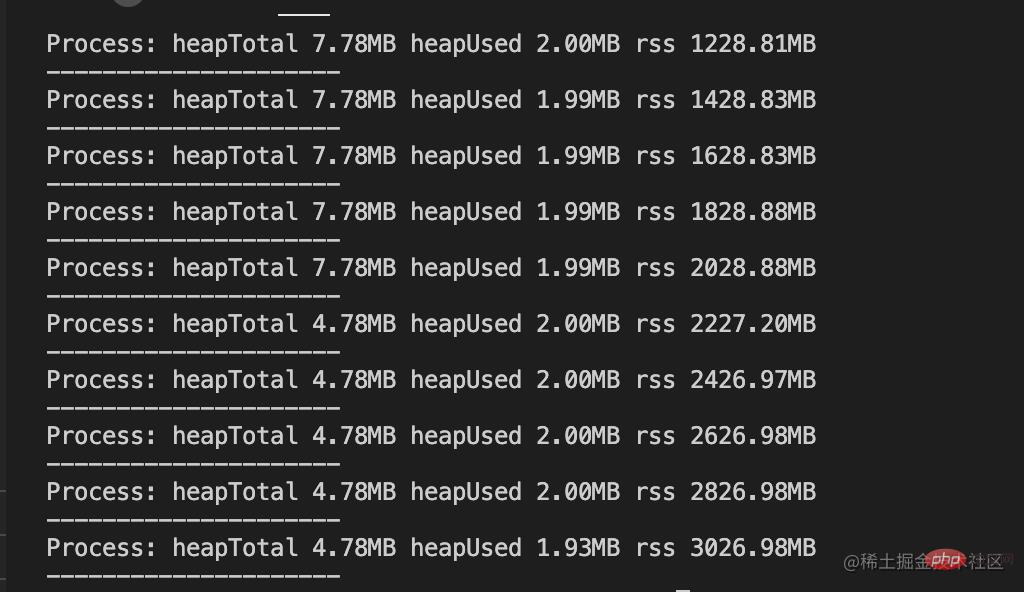
内存没有溢出,改造后的输出结果中,heapTotal与heapUsed的变化极小,唯一变化的是rss的值,并且该值已经远远超过v8的限制值。原因是Buffer对象不同于其它对象,它不经过v8的内存分配机制,所以也不会有堆内存的大小限制。意味着利用堆外内存可以突破内存限制的问题
Node的内存主要由通过v8进行分配的部分和Node自行分配的部分构成。受v8的垃圾回收限制的只要是v8的堆内存。
4. 内存泄漏
Node对内存泄漏十分敏感,内存泄漏造成的堆积,垃圾回收过程中会耗费更多的时间进行对象扫描,应用响应缓慢,直到进程内存溢出,应用崩溃。
在v8的垃圾回收机制下,大部分情况是不会出现内存泄漏的,但是内存泄漏通常产生于无意间,排查困难。内存泄漏的情况不尽相同,但本质只有一个,那就是应当回收的对象出现意外而没有被回收,变成了常驻在老生代中的对象。通常原因有如下几个:
- 缓存
- 队列消费不及时
- 作用域未释放
4.1 慎将内存当缓存用
缓存在应用中的作用十分重要,可以十分有效地节省资源。因为它的访问效率要比 I/O 的效率高,一旦命中缓存,就可以节省一次 I/O时间。
对象被当作缓存来使用,意味着将会常驻在老生代中。缓存中存储的键越多,长期存活的对象也就越多,导致垃圾回收在进行扫描和整理时,对这些对象做无用功。
Js开发者喜欢用对象的键值对来缓存东西,但这与严格意义上的缓存又有着区别,严格意义的缓存有着完善的过期策略,而普通对象的键值对并没有。是一种以内存空间换CPU执行时间。示例代码如下:
var cache = {};
var get = function (key) {
if (cache[key]) {
return cache[key];
} else {
// get from otherwise
}
};
var set = function (key, value) {
cache[key] = value;
};所以在Node中,拿内存当缓存的行为应当被限制。当然,这种限制并不是不允许使用,而是要小心为之。
4.1.1 缓存限制策略
为了解决缓存中的对象永远无法释放的问题,需要加入一种策略来限制缓存的无限增长。可以实现对键值数量的限制。下面是其实现:
var LimitableMap = function (limit) {
this.limit = limit || 10;
this.map = {};
this.keys = [];
};
var hasOwnProperty = Object.prototype.hasOwnProperty;
LimitableMap.prototype.set = function (key, value) {
var map = this.map;
var keys = this.keys;
if (!hasOwnProperty.call(map, key)) {
if (keys.length === this.limit) {
var firstKey = keys.shift();
delete map[firstKey];
}
keys.push(key);
}
map[key] = value;
};
LimitableMap.prototype.get = function (key) {
return this.map[key];
};
module.exports = LimitableMap;记录键在数组中,一旦超过数量,就以先进先出的方式进行淘汰。
4.1.2 缓存的解决方案
直接将内存作为缓存的方案要十分慎重。除了限制缓存的大小外,另外要考虑的事情是,进程之间无法共享内存。如果在进程内使用缓存,这些缓存不可避免地有重复,对物理内存的使用是一种浪费。
如何使用大量缓存,目前比较好的解决方案是采用进程外的缓存,进程自身不存储状态。外部的缓存软件有着良好的缓存过期淘汰策略以及自有的内存管理,不影响Node进程的性能。它的好处多多,在Node中主要可以解决以下两个问题。
- 将缓存转移到外部,减少常驻内存的对象的数量,让垃圾回收更高效。
- 进程之间可以共享缓存。
目前,市面上较好的缓存有Redis和Memcached。
4.2 关注队列状态
队列在消费者-生产者模型中经常充当中间产物。这是一个容易忽略的情况,因为在大多数应用场景下,消费的速度远远大于生产的速度,内存泄漏不易产生。但是一旦消费速度低于生产速度,将会形成堆积, 导致Js中相关的作用域不会得到释放,内存占用不会回落,从而出现内存泄漏。
解决方案应该是监控队列的长度,一旦堆积,应当通过监控系统产生报警并通知相关人员。另一个解决方案是任意异步调用都应该包含超时机制,一旦在限定的时间内未完成响应,通过回调函数传递超时异常,使得任意异步调用的回调都具备可控的响应时间,给消费速度一个下限值。
5. 内存泄漏排查
常见的工具
- v8-profiler: 可以用于对V8堆内存抓取快照和对CPU进行分析
- node-heapdump: 允许对V8堆内存抓取快照,用于事后分析
- node-mtrace: 使用了GCC的mtrace工具来分析堆的使用
- dtrace:有完善的dtrace工具用来分析内存泄漏
- node-memwatch
6. 大内存应用
由于Node的内存限制,操作大文件也需要小心,好在Node提供了stream模块用于处理大文件。
stream模块是Node的原生模块,直接引用即可。stream继承自EventEmitter,具备基本的自定义事件功能,同时抽象出标准的事件和方法。它分可读和可写两种。Node中的大多数模块都有stream的应用,比如fs的createReadStream()和createWriteStream()方法可以分别用于创建文件的可读流和可写流,process模块中的stdin和stdout则分别是可读流和可写流的示例。
由于V8的内存限制,我们无法通过fs.readFile()和fs.writeFile()直接进行大文件的操作,而改用fs.createReadStream()和fs.createWriteStream()方法通过流的方式实现对大文件的操作。下面的代码展示了如何读取一个文件,然后将数据写入到另一个文件的过程:
var reader = fs.createReadStream('in.txt');
var writer = fs.createWriteStream('out.txt');
reader.on('data', function (chunk) {
writer.write(chunk);
});
reader.on('end', function () {
writer.end();
});
// 简洁的方式
var reader = fs.createReadStream('in.txt');
var writer = fs.createWriteStream('out.txt');
reader.pipe(writer);可读流提供了管道方法pipe(),封装了data事件和写入操作。通过流的方式,上述代码不会受到V8内存限制的影响,有效地提高了程序的健壮性。
如果不需要进行字符串层面的操作,则不需要借助V8来处理,可以尝试进行纯粹的Buffer操作,这不会受到V8堆内存的限制。但是这种大片使用内存的情况依然要小心,即使V8不限制堆内存的大小,物理内存依然有限制。
更多node相关知识,请访问:nodejs 教程!
以上就是一文聊聊Node中的内存控制的详细内容,转载自php中文网


发表评论 取消回复