
一、需求背景
最近项目需要做排行榜功能,实现员工邀请用户注册排行榜,要求是实时更新,查询要快。员工所属支行、二级行、省行,界面要根据条件显示排名数据。效果如下图所示:
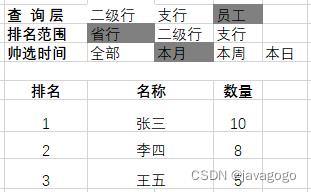
原型图展示比较随意,用excel随便写了一下,凑合着看。
二、实现思路
1、利用数据库
建一张统计表,字段包括:邀请人、邀请人所属支行、邀请人所属二级行、被邀请人、注册时间等关键信息,用于sql统计排名,根据条件使用group by相关字段,比较简单,这个大家应该清楚。
数据量小,统计效率还可以。但是支行下有十几万员工,一个员工邀请10个就百万数据,如果更多,数据就更大了,统计效率不高。下面重点讨论用第二种方式实现。
2、利用redis
我们都知道redis基于内存实现的,查询效率极高,且支持多种数据类型,其中zset是本次实现功能的关键。
- ZSet也是String类型元素的集合,且不允许重复的成员;
- 不同的是每个元素都会关联一个double类型的分数,刚好也是我们需要的邀请用户数;
- 通过分数来为集合中的成员进行排序。ZSet的成员是唯一的,但分数(score)却可以重复;
基于上面的特性,满足我们本次的需求。好了,说了一大堆废话,下面将进入正题。
首先,捋一下查询条件,根据前面的效果图,可以看出有以下几种情况:
- 二级行的全部排名以及日周月榜排名
- 支行在省行的全部排名以及日周月榜排名
- 支行在二级行的全部排名以及日周月榜排名
- 员工在省行的全部排名以及日周月榜排名
- 员工在二级行的全部排名以及日周月榜排名
- 员工在支行的全部排名以及日周月榜排名
基于redis的Zset函数incrementScore,我们很快就能发现,其实实现各个排名,只要把key规定好即可,例如:
- 员工在省行的全部排名key,可以设置为 rank:employee:省行
- 员工在省行的日排行榜key,可以设置为 rank:emploee:省行:当天日期
下面我们来实现其中的上面的两个排行:
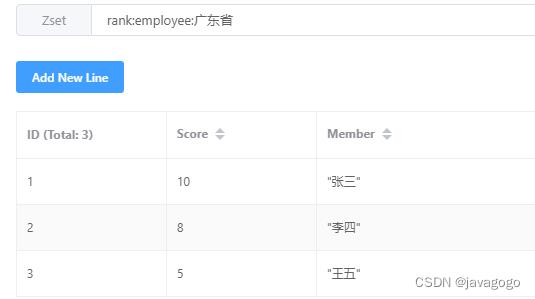
String key = "rank:employee:广东省";
redisTemplate.opsForZSet().incrementScore(key, "张三", 10);
redisTemplate.opsForZSet().incrementScore(key, "李四", 8);
redisTemplate.opsForZSet().incrementScore(key, "王五", 5);执行完后,redis会保存为如下数据:
这样的话,有了上面的数据,可以用redis的提供的函数把排行榜查出来,代码如下:
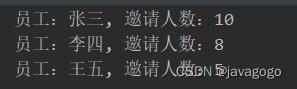
String key = "rank:employee:广东省";
Set<ZSetOperations.TypedTuple<String>> set = redisTemplate.opsForZSet().reverseRangeWithScores(key, 0, -1);
JSONArray jsonArray = JSONObject.parseArray(JSONObject.toJSONString(set));
for(int i = 0, size = jsonArray.size(); i < size; i++) {
JSONObject o = JSONObject.parseObject(jsonArray.get(i).toString());
System.out.println("员工:" + o.getString("value") + ", 邀请人数:" + o.getLongValue("score"));
}reverseRangeWithScores方法接收三个参数,第一个是key,后面两个是分页查询,起始是从0开始,-1表示全部,如果设置为0,4,那么就是查询前5条记录,查出结果如下:
以上就实现了员工在省行的排名。类似的,员工要实现在省行的日榜,代码如下:
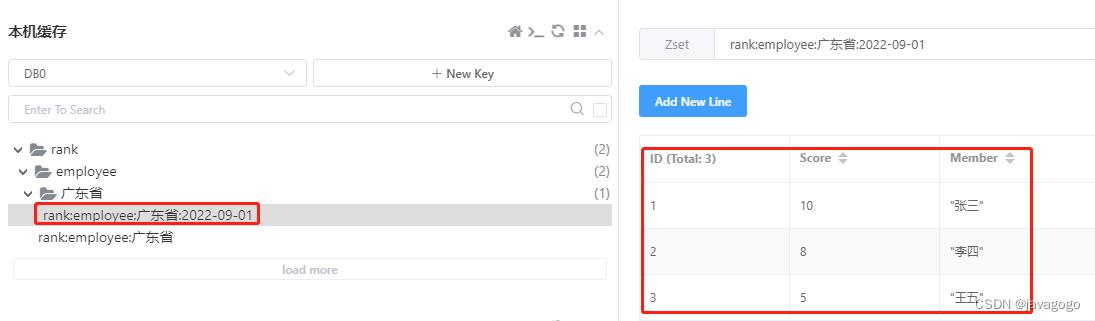
String key = "rank:employee:广东省:2022-09-01";
redisTemplate.opsForZSet().incrementScore(key, "张三", 10);
redisTemplate.opsForZSet().incrementScore(key, "李四", 8);
redisTemplate.opsForZSet().incrementScore(key, "王五", 5);执行完后,redis会保存为如下数据(这里我多设置了前一天的数据):
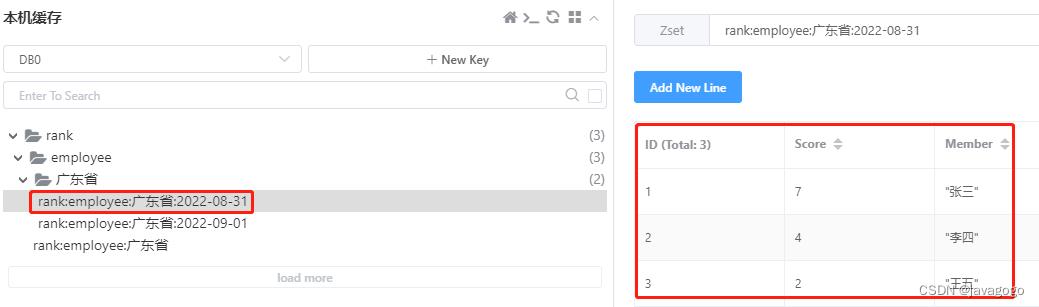
一样的,用reverseRangeWithScores方法可以把上面的结果查出来。
至于周榜、月榜,可以把每一天的数据累加起来,再做个排名,redis已经帮我们实现了这个功能,代码如下:
Date date = DateUtil.date();
//获取本周的第一天
DateTime beginOfWeek = DateUtil.beginOfWeek(date);
//到今天一共有几天
long diffDay = DateUtil.between(date, beginOfWeek, DateUnit.DAY) + 1;
List<String> keys = new ArrayList<>();
for(int i = 0; i < diffDay; i++) {
//把需要查询的天数放一起
keys.add("rank:employee:广东省:" + DateUtil.formatDate(DateUtil.offsetDay(beginOfWeek, i)));
}
//redis使用unionAndStore做合并,将结果集放在另一个的key,也就是第三个参数
redisTemplate.opsForZSet().unionAndStore("weekRank", keys, "employeeRankWeek");
//查询结果集用employeeRankWeek这个key
Set<ZSetOperations.TypedTuple<String>> set = redisTemplate.opsForZSet().reverseRangeWithScores("employeeRankWeek", 0, -1);
JSONArray jsonArray = JSONObject.parseArray(JSONObject.toJSONString(set));
for(int i = 0, size = jsonArray.size(); i < size; i++) {
JSONObject o = JSONObject.parseObject(jsonArray.get(i).toString());
System.out.println("员工:" + o.getString("value") + ", 本周邀请人数:" + o.getLongValue("score"));
}注意代码里面说的,redis会把结果合并到另一个key,在redis上也可以看到,如下图:
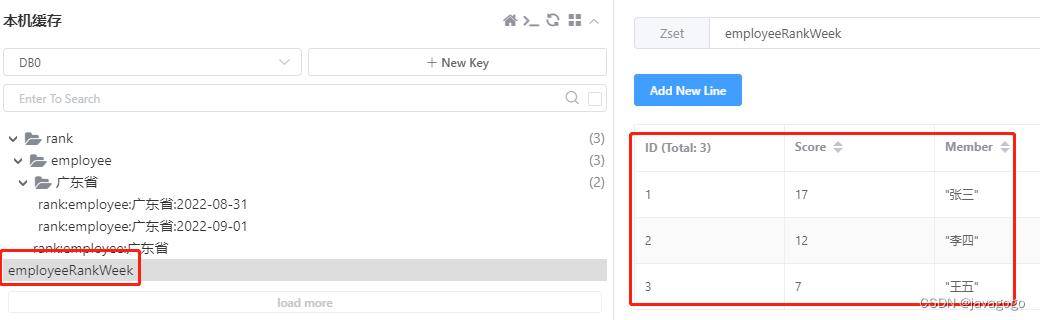
查出来的结果如下图:

其实我们会发现,本周榜、本月榜无需保存每一天的数据,只要把key设置为本周或本月的第一天就可以,因为添加数据的那一刻就知道是哪一周或哪月了。
例如:key = rank:employee:广东省:2022-08-29,8月29日是本周的第一天,无论你在接下来一周内邀请多少人,都是在本周内完成的,在这个基础上累加邀请数量即可。本月榜的逻辑也是一样。
查询的时候,获取当前时间本周或本月的第一天,就可以实现本周、本月排行了。
String key = "rank:employee:广东省";
Date date = DateUtil.date();
String week = DateUtil.formatDate(DateUtil.beginOfWeek(date));
String month = DateUtil.formatDate(DateUtil.beginOfMonth(date));
//周榜
redisTemplate.opsForZSet().incrementScore(key+":week:"+week, "张三", 17);
//月榜
redisTemplate.opsForZSet().incrementScore(key+":month:"+month, "张三", 17);
当然了,如果要查询历史的排行,这种设计就满足不了了,还是要保存每天的数据才行。
总结
到此这篇关于使用redis实现排行榜功能的文章就介绍到这了,更多相关redis实现排行榜功能内容请搜索萤火虫技术以前的文章或继续浏览下面的相关文章希望大家以后多多支持萤火虫技术!



发表评论 取消回复