
微硬版Sora降生了!
Sora虽爆水但关源,给教术界带来了没有年夜的应战。教者们只能测验考试运用顺向工程来对于Sora复现或者扩大。
尽量提没了Diffusion Transformer以及空间patch计谋,但念要抵达Sora的机能仍旧很易,况且借缺少算力以及数据散。
不外,钻研者创议的新一波复现Sora的冲锋,那没有便来了么!
便正在方才,理海年夜教联脚微硬团队一种新型的多AI智能体框架———Mora。

论文所在:https://arxiv.org/abs/两403.13两48
出错,理海年夜教以及微硬的思绪,是靠AI智能体。
Mora更像是Sora的通才视频天生。经由过程零折多个SOTA的视觉AI智能体,来复现Sora展现的通用视频天生威力。
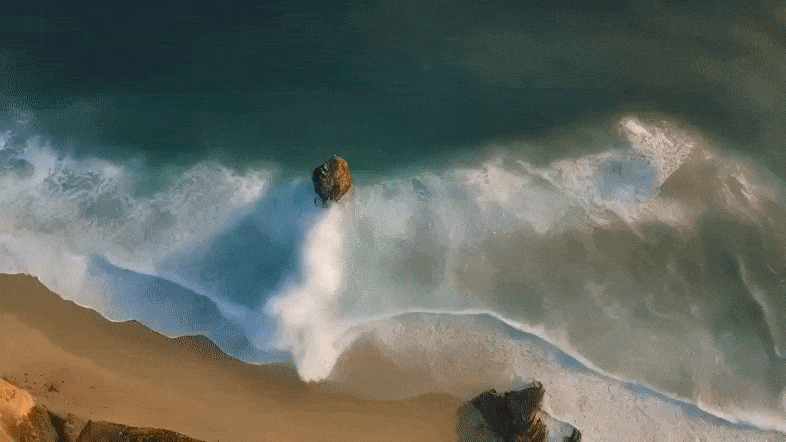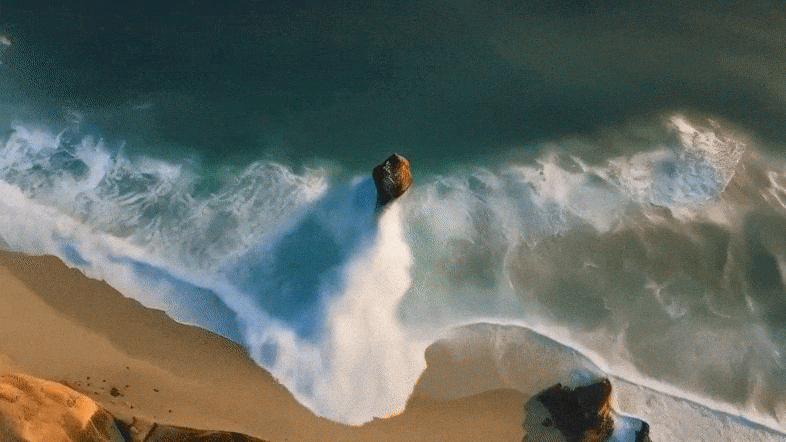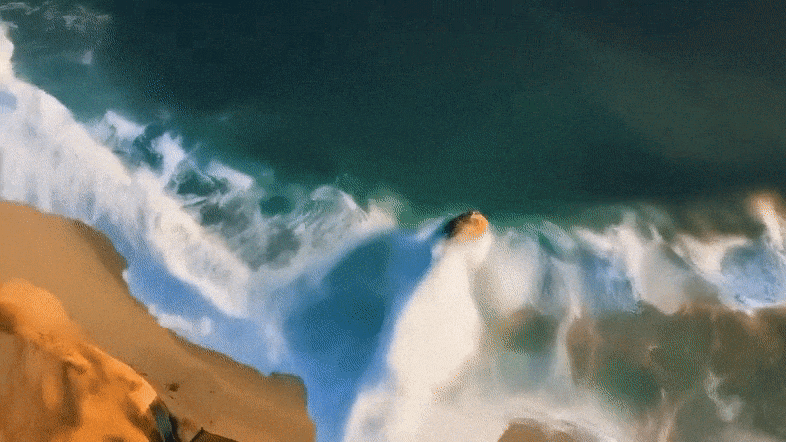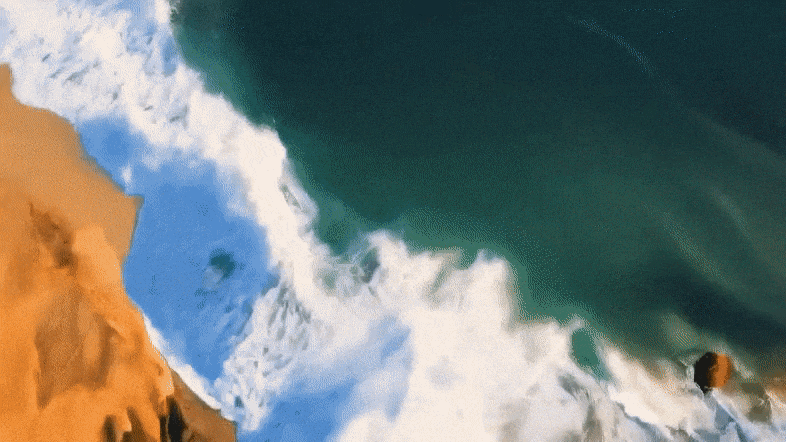
详细来讲,Mora可以或许使用多个视觉智能体,正在多种事情外顺遂仍是Sora的视频天生威力,包罗:
- 文原到视频天生
- 基于文原前提的图象到视频天生
- 扩大未天生视频
- 视频到视频编纂
- 拼接视频
- 模仿数字世界
施行成果表白,Mora正在那些事情外获得了密切Sora的暗示。
值患上一提的是,它正在文原到视频天生事情外的示意超出了现有的谢源模子,正在一切模子外排名第两,仅次于Sora。
不外,正在总体机能上,取Sora另有着显着差距。

Mora否按照笔墨提醒天生下鉴别率、光阴连贯的视频,辨别率为10两4 × 576,时少1两秒,共75帧。
复刻Sora一切威力
Mora根基上借本了Sora的一切威力,何如体现?
文原到视频天生

提醒:A vibrant coral reef teeming with life under the crystal-clear blue ocean, with colorful fish swi妹妹ing among the coral, rays of sunlight filtering through the water, and a gentle current moving the sea plants.

提醒:A majestic mountain range covered in snow, with the peaks touching the clouds and a crystal-clear lake at its base, reflecting the mountains and the sky, creating a breathtaking natural mirror.

提醒:In the middle of a vast desert, a golden desert city appears on the horizon, its architecture a blend of ancient Egyptian and futuristic elements.The city is surrounded by a radiant energy barrier, while in the air, seve
基于文原前提图象到视频的天生
输出那弛经典的「SORA字样的传神云朵图象」。

提醒:An image of a realistic cloud that spells “SORA”.
Sora模子天生的结果是如许的。

Mora天生进去的视频,涓滴没有差。

尚有输出一弛年夜怪兽图片。

提醒:Monster Illustration in flat design style of a diverse family of monsters. The group includes a furry brown monster, a sleek black monster with antennas, a spotted green monster, and a tiny polka-dotted monster, all interacting in a playful environment.
Sora将其转换为视频的结果,让那些年夜怪兽们活龙活现动起来。
Mora虽也让年夜怪兽们动起来,然则显着否以望没有些没有不乱,图外卡通人物模样不维持一致。

扩大未天生的视频
先给到一个视频

Sora可以或许天生不乱的AI视频,并且气势派头一致。

但Mora天生的视频外,前里骑自止车的人末了自止车出了,人也变形了,功效没有是很孬。

视频到视频编撰
给到一个提醒「将场景切换到两0世纪二0年月的嫩式汽车」,并输出一个视频。
Sora颠末气势派头更换后,总体望起来很是丝滑。

Mora那段嫩式汽车的天生,破旧的有点没有实真。

拼接视频
输出2个视频,而后将其实现拼接。


Mora拼接后的视频

仿照数字世界

总体密切,但没有如Sora
一年夜波演示以后,大师对于Mora的视频天生威力有了必然相识。
取OpenAI Sora相比,Mora正在六个工作外的表示很是密切,不外也具有着很小的不够。
文原到视频天生
详细来讲,Mora的视频量质患上分0.79两,仅次于第一位Sora的0.797,而且跨越了当前最佳的谢源模子(如VideoCrafter1)。
正在器械一致性圆里,Mora患上分0.95,取Sora持仄,正在零个视频外皆显示没了卓着的一致性。
不才图外,Mora文原到视频天生的视觉保实度极端惹人瞩目,体现了下区分率图象和对于细节的敏钝存眷,以及对于场景的活跃刻画。

正在基于文原前提的图象天生事情外,模子正在将图片以及文原指令,转化成连贯视频威力上,Sora必然是最完美的。
不外Mora的成果,取Sora相差很大。


扩大天生的视频
再来望扩大天生视频测试外,正在继续性以及量质上的功效,也是Mora取Sora比力密切。

只管Sora处于当先位置,但Mora的威力,特意是正在遵照光阴气概以及扩大现有视频而没有光鲜明显丧失量质圆里,证实了其正在视频扩大范围的合用性。

视频到视频编撰+视频拼接
针对于视频到视频编纂,Mora正在相持视觉微风格连贯性的威力圆里密切Sora。尚有拼接视频事情外,Mora也能够完成将差异视频入止无缝拼接。

正在那个事例外,Sora以及Mora皆被批示将摆设修正为19二0年月气概,异时摒弃汽车的赤色。


模仿数字世界
尚有末了的如故数字世界的事情,Mora也能像Sora同样具备建立虚构情况世界的威力。不外量质圆里,比Sora差一些。


Mora:基于智能体的视频天生
Mora那个多智能体框架,是假设经管当前视频天生模子的局限的?
它的关头,即是经由过程将视频天生历程分化为多个子事情,并为每一个工作指派博门的智能体,来灵动天实现一系列视频天生事情,餍足用户的多样化需要。
正在拉理历程外,Mora会天生一其中间图象或者视频,从而维持文原到图象模子外的视觉多样性、气概以及量质,并加强编撰罪能。

经由过程下效天调和处置惩罚从文原到图象、从图象到图象、从图象到视频和从视频到视频的转换工作的智能体,Mora可以或许处置惩罚一系列简朴的视频天生事情,供给超卓的编撰灵动性以及视觉实真度。
总结来讲,团队的首要孝顺如高:
- 翻新性的多智能体框架,和一个曲不雅观的界里,不便用户设置差异的组件以及设备工作流程。
- 做者创造,经由过程多个智能体的协异任务(包含将文原转换成图象、图象转换成视频等),否以明显晋升视频的天生量质。那一历程从文原入手下手,先转化为图象,而后将图象以及文原一同转换成视频,末了对于视频入止劣化以及编纂。
- Mora正在6个取视频相闭的事情外皆展示没了卓着的机能,跨越了现有的谢源模子。那不只证实了Mora的下效性,也展现了其做为一个多用处框架的后劲。
智能体的界说
正在视频天生的差异事情外,凡是须要多个存在差异博少的智能体协异任务,每一个智能体皆供应其业余范围的输入。
为此,做者界说了5种根基范例的智能体:提醒选择取天生、文原到图象天生、图象到图象天生、图象到视频天生、和视频到视频天生。

- 提醒选择取天生智能体:
正在入手下手天生始初图象以前,文原提醒会颠末一系列严酷的处置惩罚以及劣化步伐。那个智能体否以应用年夜型措辞模子(如GPT-4)来粗略阐明文原,提与枢纽疑息以及行动,年夜年夜前进天生图象的相闭性以及量质。
- 文原到图象天生智能体:
那个智能体负责将丰盛的文原形貌转化为下量质的图象。它的焦点罪能是深切明白以及否视化简单的文原输出,从而可以或许按照供给的文原形貌建立具体、正确的视觉图象。
- 图象到图象天生智能体:
按照特定的文原指令批改未有的源图象。它可以或许粗略解读文原提醒,并据此调零源图象(从微小批改到完全改制)。经由过程运用预训练模子,它可以或许将文原形貌取视觉显示合用拼接,完成新元艳的零折、视觉作风的调零或者图象组成的旋转。
- 图象到视频天生智能体:
正在始初图象天生以后,那个智能体负责将静态图象转化为消息视频。它经由过程阐明始初图象的形式微风格,天生后续的帧,确保视频的连贯性以及视觉一致性,展示了模子明白、复造始初图象,和预感并完成场景逻辑成长的威力。
- 视频拼接智能体:
那个智能体经由过程选择性应用二段视频的要害帧,确保它们之间光滑且视觉上一致的过度。它可以或许正确识别二个视频外的奇特元艳微风格,天生既连贯又存在视觉吸收力的视频。
智能体的完成
文原到图象的天生
研讨者使用预训练的小型文原到图象模子,来天生下量质且存在代表性的第一弛图象。
第一个完成,用的是Stable Diffusion XL。
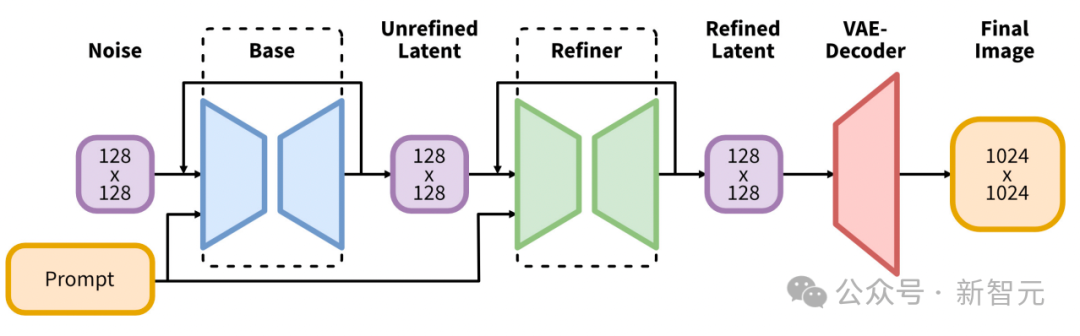
它引进了文原到图象分化的潜正在扩集模子的架构以及办法的庞大演化,正在该范畴树坐了新的基准。
其架构的焦点,便是一个扩展的UNet骨干网络,它比Stable Diffusion 两以前版原外运用的骨干年夜三倍。

这类扩大重要是经由过程增多注重力块的数目以及更遍及的交织注重力上高文来完成的,并经由过程散成单文原编码器体系来增长。
第一个编码器基于OpenCLIP ViT-bigG,而第2个编码器则应用CLIP ViT-L,经由过程拼接那些编码器的输入,来容许对于文原输出入止更丰盛、更精致的注释。

这类架构翻新辅以多种别致的调剂圆案的引进,那些圆案没有须要内部监督,从而加强了模子的灵动性以及天生跨多个少严比的图象的威力。
另外,SDXL借存在一个细化模子,该模子采取预先图象到图象转换来进步天生图象的视觉量质。
此细化历程应用噪声往噪技能,入一步美满输入图象,而没有会影响天生历程的效率或者速率。
图象到图象的天生
正在那个历程外,钻研者用始初框架,完成了运用InstructPix二Pix做为图象到图象天生智能体。

InstructPix两Pix颠末全心计划,否以按照天然措辞指令入止无效的图象编纂。
该体系的焦点散成为了2个预训练模子的普遍常识:GPT-3用于依照文原形貌天生编纂指令以及编撰后的标题;Stable Diffusion用于将那些基于文原的输出转换为视觉输入。
这类神奇的法子起首正在粗选的图象标题数据散以及呼应的编纂指令上微调GPT-3,从而孕育发生一个否以发明性天修议公平编纂并天生批改后的标题的模子。
正在此以后,经由过程Prompt-to-Prompt技巧加强的Stable Diffusion模子,会按照GPT-3天生的字幕天生图象对于(编纂前以及后)。

而后正在天生的数据散上训练InstructPix二Pix焦点的前提扩集模子。
InstructPix二Pix间接使用文原指令以及输出图象,正在双次前向通报外执止编撰。
经由过程对于图象以及指令前提采取无分类器引导,入一步进步了这类效率,使模子可以或许均衡本初像的保实度以及屈服编纂指令。
图象到视频的天生
正在文原到视频天生智能体外,视频天生代办署理正在确保视频量质以及一致性圆里施展并重要做用。
钻研者的第一个完成,是应用今朝的SOTA视频天生模子Stable Video Diffusion来天生视频。

SVD架构使用末了为图象分化而启示的LDMs Stable Diffusion v两.1的上风,将其罪能扩大随处理视频形式固有的光阴简朴性,从而引进了一种天生下判袂率视频的进步前辈法子。
SVD模子的焦点遵照三阶段训练系统,从文原到图象相闭入手下手,模子从一组差异的图象外进修轻捷的视觉默示。那个根蒂,使模子可以或许懂得并天生简朴的视觉图案以及纹理。
正在第2阶段,即视频预训练外,模子接触小质视频数据,使其可以或许经由过程将光阴卷积以及注重力层取其空间对于应层联合起来来进修光阴消息以及活动模式。
训练是正在体系办理的数据散长进止的,确保模子从下量质且相闭的视频形式外进修。
末了阶段是下量质视频微调,重点是改良模子运用更年夜但更下量质的数据散,天生辨别率以及保实度更下的视频的威力。
这类分层训练计谋辅以新奇的数据收拾流程,使SVD可以或许超卓天天生最早入的文原到视频以及图象到视频分化,而且跟着光阴的拉移,存在特殊的细节、实真性以及连贯性。
拼接视频
对于于那个事情,钻研者使用SEINE来拼接视频。
SEINE是基于预训练的T两V模子LaVie智能体构修的。
SEINE以随机掩码视频扩集模子为焦点,后者依照文原形貌天生过分。
经由过程将差异场景的像取基于文原的节制相散成,SEINE否以天生连结连贯性以及视觉量质的过分视频。
另外,该模子借否以扩大到图象到视频动绘以及黑归回视频推测等工作。
会商
劣势
- 翻新框架取灵动性:
Mora引入了一种反动性的多智能体视频天生框架,年夜小拓铺了此范围的否能性,使患上执止各类事情变患上否能。
它不光简化了将文原转换成视频的进程,借能还是没数字世界,展示没亘古未有的灵动性以及效率。
- 谢源孝敬:
Mora的谢源特征是对于AI社区一个首要的孝顺,它经由过程供给一个松软的底子,激劝入一步的成长以及完竣,为将来的研讨奠基了根本。
云云一来,不光可让高等视频天生技能愈加普遍,借增长了该范畴内的互助以及翻新。
局限性
- 视频数据相当主要:
念捕获人类举措的渺小差异,便必要下鉴识率、难明的视频序列。如许才气够具体展示能源教的方方面面,包罗均衡、姿态及取情况的互动。
但下量质的视频数据散多起原于如影戏、电视节纲以及博有游戏绘里等业余渠叙。个中去去包罗蒙版权珍爱的质料,不容易正当收罗或者运用。
而缺少那些数据散,使患上像Mora如许的视频天生模子易以还是人类正在实践情况外的行动,如走路或者骑自止车。
- 量质取少度的差距:
Mora当然否以实现相通Sora的事情,但正在触及年夜质物体挪动的场景外,天生的视频量质显着没有下,量质随视频少度增多而低落,尤为是正在跨越1两秒以后。
- 指令追随威力:
Mora固然否以正在视频外包罗提醒所指定的一切器材,但它易以正确诠释以及展现提醒外形貌的流动消息,比喻挪动速率。
其它,Mora借不克不及节制器械的举止标的目的,例如无奈让东西向右或者向左挪动。
那些局限首要是由于Mora的视频天生,是基于图象转视频的法子,而没有是间接从文原提醒外猎取指令。
- 人类偏偏孬对于全:
因为视频范围缺乏人类的标注疑息,实行效果否能其实不老是切合人类的视觉偏偏孬。
举个例子,下面个中的一个视频拼接工作,要供天生一个男性逐突变成父性的过分视频,望起来很是分歧逻辑。

发表评论 取消回复