
最近几年,基于 Transformer 的架构在多种任务上都表现卓越,吸引了世界的瞩目。使用这类架构搭配大量数据,得到的大型语言模型(LLM)等模型可以很好地泛化用于真实世界用例。
尽管有如此成功,但基于 Transformer 的架构和 LLM 依然难以处理规划和推理任务。之前已有研究证明 LLM 难以应对多步规划任务或高阶推理任务。
为了提升 Transformer 的推理和规划性能,近些年研究社区也提出了一些方法。一种最常见且有效的方法是模拟人类的思考过程:先生成中间「思维」,然后再输出响应。比如思维链(CoT)提示法就是鼓励模型预测中间步骤,进行按步骤的「思考」。思维树(ToT)则使用了分支策略和评判方法,让模型生成多个不同的思维路径,然后从中选出最佳路径。尽管这些技术通常是有效的,但也有研究表明,在很多案例中,这些方法会让模型的性能下降,原因包括自我强制(self-enforcing)。
另一方面,在一个数据集上有效的技术可能无法很好地处理其它数据集,原因可能包括所涉及的推理类型发生了变化,比如从空间推理变成了数学推理或常识推理。
相较之下,传统的符号式规划和搜索技术却能表现出很好的推理能力。此外,这些传统方法计算得到的解决方案通常有形式上的保证,因为符号规划算法通常遵循明确定义的基于规则的搜索过程。
为了让 Transformer 具备复杂推理能力,Meta FAIR 田渊栋团队近日提出了 Searchformer。

- 论文标题:Beyond A∗: Better Planning with Transformers via Search Dynamics Bootstrapping
- 论文地址:https://baitexiaoyuan.oss-cn-zhangjiakou.aliyuncs.com/itnew/zxekvg1ehro.pdf style="text-align: justify;">Searchformer 是一种 Transformer 模型,但针对迷宫导航和推箱子等多步规划任务,它却能计算出最优规划并且所用搜索步骤数也能远少于 A∗ 搜索等符号规划算法。
为了做到这一点,该团队提出了一种新方法:搜索动态引导(search dynamics bootstrapping)。该方法首先是训练一个 Transformer 模型来模仿 A∗ 的搜索过程(如图 1 所示,然后对其进行微调,使其能用更少的搜索步数找到最优规划。

更详细地说,第一步,训练一个模仿 A∗ 搜索的 Transformer 模型。这里,该团队的做法是针对随机生成的规划任务实例运行 A* 搜索。在执行 A∗ 时,该团队会记录执行的计算和最优规划并将其整理成词序列,即 token。这样一来,所得到的训练数据集就包含了 A∗ 的执行轨迹并编码了有关 A∗ 本身的搜索动态的信息。然后,训练一个 Transformer 模型,让其能针对任意规划任务沿最优规划生成这些 token 序列。
第二步,使用专家迭代(expert iteration)方法进一步提升使用上述经过搜索增强的序列(包含 A∗ 的执行轨迹)训练的 Searchformer。专家迭代方法可让 Transformer 凭借更少的搜索步骤生成最优解。这个过程会得到一种神经规划算法,其隐式地编码在该 Transformer 的网络权重之中,并且它有很高的概率以少于 A∗ 搜索的搜索步数找到最优规划。比如说,在执行推箱子任务时,新模型能解答 93.7% 的测试任务,同时搜索步数比 A∗ 搜索平均少 26.8%。
该团队表示:这为 Transformer 超越传统符号规划算法铺平了道路。
实验
为了更好地理解训练数据和模型参数量对所得模型性能的影响,他们进行了一些消融研究。
他们使用了两类数据集训练模型:一种的 token 序列中只包含解(solution-only,其中只有任务描述和最终规划);另一种则是搜索增强型序列(search-augmented,其中包含任务描述、搜索树动态和最终规划)。
实验中,该团队使用了 A∗ 搜索的一种确定性和非确定性变体来生成每个序列数据集。
迷宫导航
在第一个实验中,该团队训练了一组编码器 - 解码器 Transformer 模型来预测 30×30 迷宫中的最优路径。
图 4 表明,通过预测中间计算步骤,可在数据量少时获得更稳健的性能表现。

图 5 给出了仅使用解训练的模型的性能。
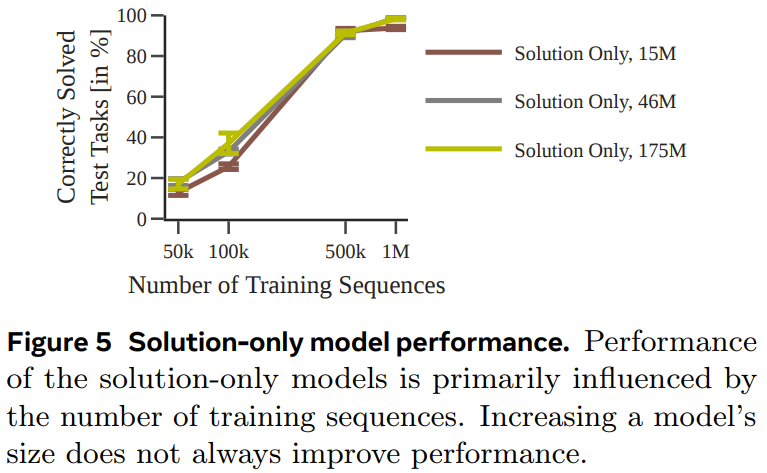
图 6 展示了任务难度对每个模型的性能的影响。
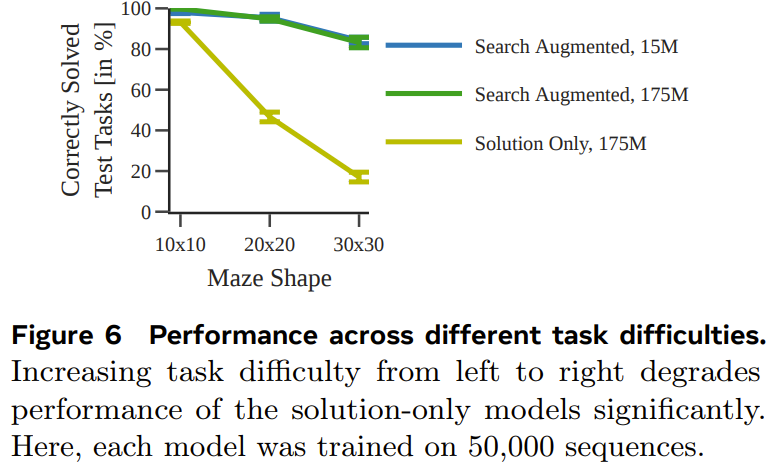
整体而言,尽管当使用的训练数据集足够大和足够多样化时,仅使用解训练的模型也能预测得到最优规划,但当数据量少时,经过搜索增强的模型的表现明显好得多,并且也能更好地扩展用于更困难的任务。
推箱子

为了测试能否在不同且更复杂的任务(具有不同的 token 化模式)上得到类似的结果,该团队还生成了一个推箱子的规划数据集进行测试。
图 7 展示了每种模型针对每个测试任务生成正确规划的概率。
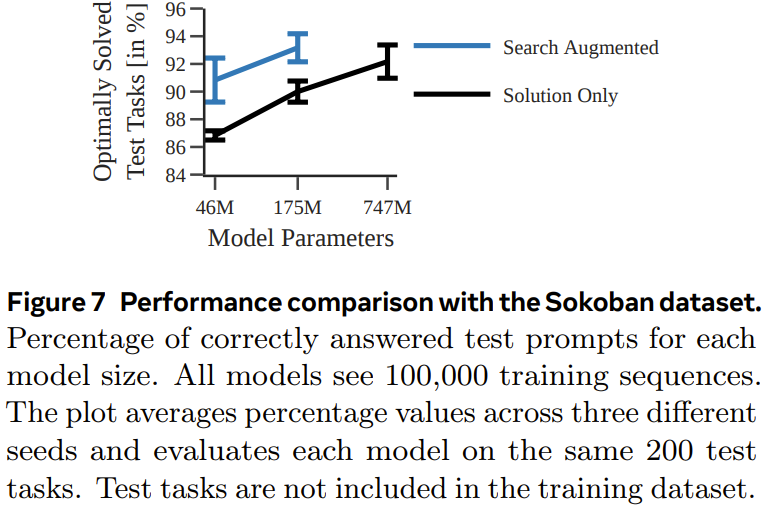
可以看到,和上一个实验一样,通过使用执行轨迹进行训练,搜索增强型模型的表现优于仅使用解训练的模型。
Searchformer:通过引导方法提升搜索动态
最后一个实验,该团队研究了搜索增强型模型可以如何迭代提升,从而凭借更少的搜索步数计算出最优规划。这里的目标是在缩短搜索轨迹长度的同时依然得到最优解。
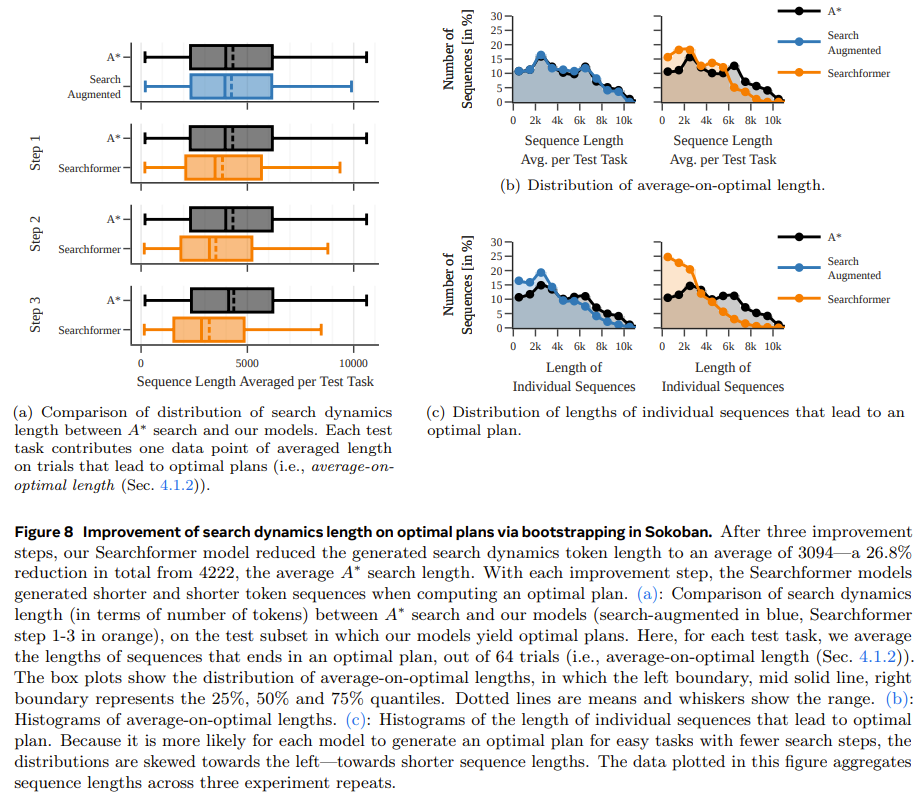
图 8 表明,新提出的搜索动态引导方法能够迭代式地缩短 Searchformer 模型生成的序列的长度。

发表评论 取消回复