
写在前面&笔者的个人理解
在算法开发中,激光雷达-相机3D目标检测遇到了过度拟合问题,这是由于违反了一些基本规则。在数据集构建的数据标注方面,本文参考了理论补充,并认为回归任务预测不应涉及来自相机分支的特征。通过采用“检测即标签”的前沿观点,本文提出了一种新的范式,称为DAL。使用最经典的初级算法,通过模仿数据标注过程构建了一个简单的预测流水线。然后,本文以最简单的方式对其进行训练,以最小化其依赖性并增强其可移植性。尽管构造和训练都很简单,但所提出的DAL范式不仅在性能上取得了重大突破,而且在所有现有方法中提供了速度和精度之间的优越权衡。凭借全面的优势,DAL会是未来工作开发和实际部署的理想基准。代码已发布,https://github.com/HuangJunJie2017/BEVDet。
尽管构造和训练简单,但提出的DAL范式不仅极大地推动了性能边界(例如,在nuScenes val集上为74.0 NDS,在nuScenes test集上为74.8 NDS),而且在所有现有方法中提供了速度和精度之间的优越权衡。本文的主要贡献可以概括如下
- 文章提出了一个前沿的视角,即“检测作为标注”,用于3D物体检测中的LiDAR-相机融合。这是对现有方法的良好补充,也是未来工作应遵循的基本规则。
- 文章遵循“检测作为标注”的观点,构建了一个名为DAL的鲁棒范例。DAL是第一个具有极其优雅的训练管道的LiDAR-Camera融合范例。此外,它极大地推动了该问题的性能边界,在推理延迟和准确性之间实现了优异的权衡。凭借全面的优势,DAL是未来工作发展和实际使用的理想基线。
- 文章指出了速度分布不可避免的不平衡问题,并提出了实例级速度增益来缓解这一问题。
算法的网络设计
从 "检测即标记 "的角度出发,模仿数据标注过程构建了一个预测管道,如下图所示。提出的管道遵循从密集到稀疏的范式。密集感知阶段的重点是特征编码和候选特征生成。使用图像编码器和点云编码器分别提取图像和点云中的特征。N 表示视图的数量。H × W 表示图像视图中特征的大小。X × Y 表示特征在鸟眼视图(BEV)中的大小。特征编码器具有经典的骨干结构(如 ResNet 和 VoxelNet)和颈部结构(如 FPN和 SECOND)。只需将密集图像的 BEV 特征与点云的 BEV 特征进行串联融合,并通过应用两个额外的残差块来预测密集热图。C 表示类别的数量。最后,选出在密集热图中预测得分领先的 K 个候选者。这样就模仿了数据标注中的候选生成过程。在此过程中,会同时使用图像和点云的特征来生成一套完整的候选数据。
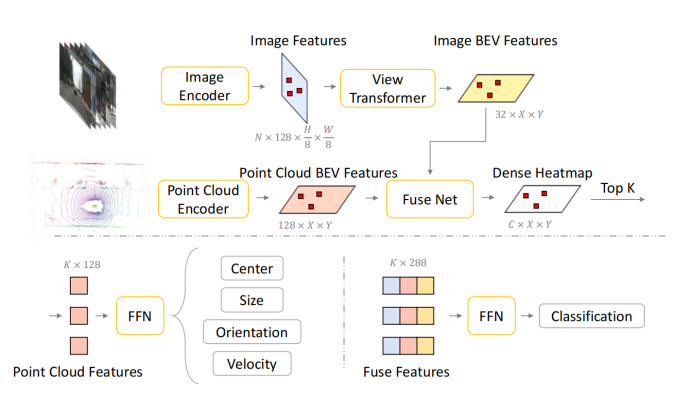
DAL范式的预测管道。将来自图像和点云的BEV特征融合在一起,生成密集的热图。提取前K个建议及其点云特征,用于回归任务预测。与图像特征、图像BEV特征和点云BEV特征融合的特征用于类别预测。根据每个建议的相应预测中心提取稀疏图像特征。
在稀疏感知阶段,首先根据候选对象在密集热图中的坐标收集每个候选对象的点云特征。然后使用简单的前馈网络(FFN)预测回归目标(例如中心、大小、方向和速度)。在这个过程中不涉及图像特征,以防止过拟合问题。最后,本文将图像特征、图像BEV特征和点云BEV特征融合在一起,生成用于类别预测的融合特征。图像BEV特征的部分是根据候选对象在密集热图中的坐标提取的,而图像特征的部分是根据预测的对象中心提取的。
除了进行一些关键修改外,DAL的预测管道从BEVFusion继承了大部分结构设计。首先,点云BEV特征和图像BEV特征在密集BEV编码器之后进行融合,而BEVFusion在之前进行融合。本文推迟融合,以最大限度地保留LiDAR分支的回归能力。然后,由于发现没有必要,去除了稀疏实例和BEV特征之间的注意力。最后,回归任务仅使用点云特征进行预测,而BEVFusion使用融合特征。
由于本文在构建预测管道时分配了适当的方式,只需要像大多数经典视觉任务一样加载在 ImageNet 上预训练的图像骨干的参数。然后本文以端到端的方式训练 DAL,只有一个阶段。只使用来自目标数据集 nuScenes的数据。通过这种方式,本文以最优雅的方式训练 DAL 模型,这在文献中很少见。
例如,DAL与TransFusion和BEVFusion共享目标和损失的设计。除此之外,本文在图像特征上添加了一个辅助分类头,以加强图像分支在搜索候选对象和区分不同类别方面的能力。这对于DAL来说非常重要,因为3D目标检测头中密集感知阶段和稀疏感知阶段的监督都有缺陷。具体来说,在密集感知阶段,图像特征会根据视图转换中的预测深度得分进行调整。反向传播中的梯度也是如此。预测深度得分有缺陷是不可避免的,监督也是如此。在稀疏感知阶段,损失计算中只涉及预测实例的图像特征,而不是所有注释目标的图像特征。具有所有注释目标监督的辅助分类头可以解决上述问题,并在一定程度上加强图像分支。在实践中,使用注释目标的重心来提取每个注释目标的稀疏特征。然后,使用另一个FFN对稀疏特征进行分类,损失计算与3D目标检测头中的分类任务相同。不进行重新加权,本文直接将辅助损失添加到现有的损失中:
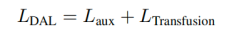
在回归任务预测中弃用图像特征不仅可以防止不可避免的性能退化,而且可以在图像空间中进行更广泛的数据增强。本文以调整大小增强为例进行解释。基于相机的3D物体检测根据其在图像视图中的大小预测目标的大小。当图像随机调整大小时,为了保持图像特征与预测目标之间的一致性,需要对预测目标进行相应的调整。然后是LiDAR-相机融合的3D物体检测中的连锁反应中的点云。因此,现有的方法总是在图像空间中使用小范围的数据增强。结果,它们远离了大多数图像2D任务(例如分类,检测,分割)中图像空间大规模数据增强的好处。
最后,本文观察到训练数据中速度分布极不平衡。如图3所示,nuScenes训练集中汽车类别的多数实例是静态的。为了调整分布,随机选择了一些静态物体,并根据预定义的速度调整其点云,如图4所示。本文仅对静态物体进行速度增强,因为可以从其带注释的边界框中轻松地识别来自多个LiDAR帧的全套点。
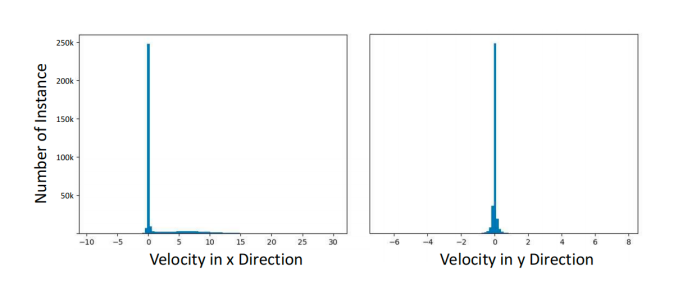
图3. nuScenes训练集中汽车类别的速度分布。
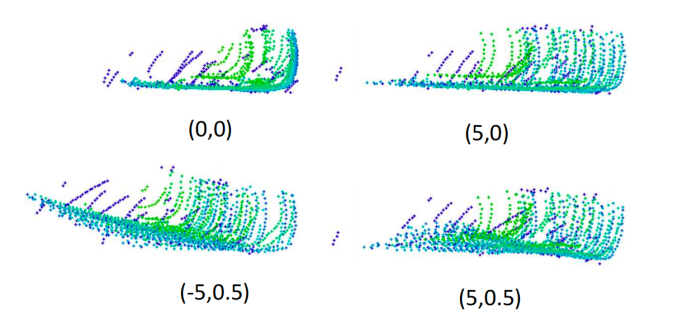
图4.使用不同的预定义速度(即(vx,vy))增强相同的静态对象
相关实验结果
数据集
本文在大规模基准nuScenes上进行全面的实验。NuScenes是验证许多室外任务的最新流行基准,如3D物体检测、占用率预测、BEV语义分割、端到端自动驾驶。它包括1000个场景,其中包含来自6个相机的图像和来自具有32束光束的LiDAR的点云。相机组具有与LiDAR一致的360度视野。这使其成为评估LiDAR-相机融合算法的首选数据集。这些场景被正式分为700/150/150个场景,用于训练/验证/测试。有10个类别的140万个注释的3D边界框:汽车、卡车、公共汽车、拖车、工程车辆、行人、摩托车、自行车、障碍物和交通锥。
评估指标
对于3D对象检测,本文报告了官方预定义的度量标准:平均精确度(mAP)、平均平移误差(ATE)、平均缩放误差(ASE)、平均方向误差(AOE)、平均速度误差(AVE)、平均属性误差(AAE)和NuScenes检测评分(NDS)。mAP类似于2D对象检测中的mAP,用于衡量精度和召回率,但基于地面上2D中心距离的匹配,而不是交集比(IOU)。NDS是其他指标的组合,用于综合判断检测能力。其余指标用于计算相应方面的阳性结果精度(例如,平移、缩放、方向、速度和属性)。
预测管道
如表2所示,本文遵循两种经典的3D对象检测范式BEVDet-R50 和CenterPoint ,分别构建图像分支和LiDAR分支,用于消融研究。此外,本文还提供了一些推荐的配置,在推理延迟和准确性之间实现了出色的权衡。

训练和评估
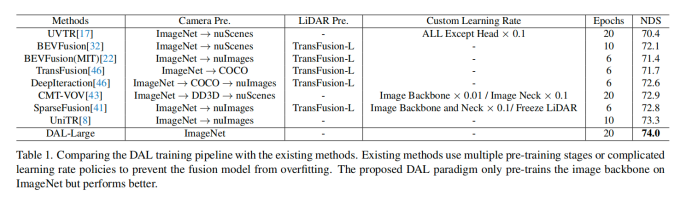
DAL模型在16个3090 GPU上以64个批处理大小进行训练。如表1所示,
与大多数需要多个预训练阶段和复杂学习率策略的现有方法不同,DAL仅从ImageNet分类任务中加载预训练权重,并使用CBGS对整个流水线进行20个epoch的训练。DAL与CenterPoint共享相同的学习率策略。具体来说,学习率通过遵循循环学习率策略进行调整,初始值为2.0×10-4。在评估过程中,本文报告了单个模型在无测试时间增广情况下的性能。默认情况下,推理速度都在单个3090 GPU上测试。BEVPoolV2 用于加速视图变换算法LSS。
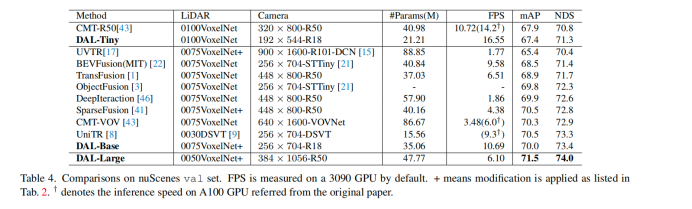
nuScenes val set的结果。如表4所示和图1所示,提出的DAL范式不仅极大地推动了性能边界,而且还提供了速度和精度之间的更好权衡。配置DAL-Large的分数为71.5 mAP和74.0 NDS,大大超过了现有的最佳记录,分别增加了+1.0 mAP和+0.7 NDS。在如此高的准确度下,DAL-Large仍然以6.10 FPS的推理速度运行。另一个推荐的配置DAL-Base以与最快的方法CMT-R50 类似的推理速度运行。其准确度大大超过了CMT-R50,分别为2.1 mAP和2.6 NDS。与CMT-R50具有相似的准确度,DAL-Tiny的加速率为54%。
nuScenes测试集的结果。本文报告了DAL-Large配置在nuScenes测试集上的性能,没有模型集成和测试时间扩展。DAL在NDS 74.8方面优于所有其他方法。
总结
本文提出了一个前沿的视角“检测作为标注”,用于激光雷达-摄像头融合的3D物体检测。DAL是按照这个视角开发的模板。DAL是一个非常优雅的范例,具有简洁的预测管道和易于训练的过程。尽管在这些方面很简单,但它极大地推动了激光雷达-摄像头融合的3D物体检测的性能边界,并在速度和精度之间实现了最佳的平衡。因此,它对未来的工作和实际应用来说都是一个很好的里程碑。
DAL中没有考虑超出激光雷达范围的对象。本文尝试过通过仅使用点云特征预测密集的热图,并将其与使用融合特征预测的热图进行比较,来区分这种情况。然后,使用另一个FFN在融合特征上预测这些实例的回归目标。然而,这种修改对最终准确性的贡献较小。这是因为 nuScenes 中只注释了具有 1 个以上激光雷达点的目标。此外,在 nuScenes 评估中,范围足够小,确保了足够的激光雷达点用于预测回归方面。
此外,nuScenes数据集中的简单分类任务限制了DAL应用SwinTransformer、DCN 和EfficientNet等高级图像骨干。开放世界分类任务要复杂得多,因此也更加困难。因此,图像分支在实践中可以利用高级图像骨干。
虽然DAL有一个无注意力的预测管道,但它只是一个揭示“检测作为标记”价值的模板。因此,本文使用最经典的算法,而不应用注意力。然而,本文并没有有意将其排除在DAL之外。相反,本文认为注意力是一种吸引人的机制,可以在许多方面进一步发展DAL。例如,本文可以应用像UniTR 这样的高级DSVT主干,应用基于注意力的LiDAR-相机融合,如CMT,以及应用基于注意力的稀疏检测范式,如DETR。
原文链接:https://baitexiaoyuan.oss-cn-zhangjiakou.aliyuncs.com/itnew/yyhqpiqrgvn

发表评论 取消回复