
Sora 问世才不到两个星期,谷歌的世界模型也来了,能力看起来更强大:它生成的虚拟世界「自主可控」。
刚刚,谷歌定义了生成式 AI 的全新范式 —— 生成式交互环境(Genie,Generative Interactive Environments)。Genie 是一个 110 亿参数的基础世界模型,可以通过单张图像提示生成可玩的交互式环境。
我们可以用它从未见过的图像进行提示,然后与自己想象中的虚拟世界进行互动。
不管是合成图像、照片甚至手绘草图,Genie 都可以从中生成无穷无尽的可玩世界。

Genie 由三个部分组成:一个潜在动作模型,用于推断每对帧之间的潜在动作;一个视频 tokenizer,用于将原始视频帧转换为离散 token;一个动态模型,用于在给定潜在动作和过去帧 token 的情况下,预测视频的下一帧。
看到这项技术发布,很多人表示:谷歌又要来领导 AI 技术了。

谷歌还提出,Genie 学到的潜在动作可以转移到真实的人类设计的环境中。在这个假设基础上,谷歌针对机器人视频训练了一个 Genie 模型,作为机器人领域潜在世界模型应用的概念验证。
被颠覆的游戏、设计、XR、机器人行业……
我们可以从四个维度来理解 Genie 的革命性意义。
首先,Genie 可以在没有动作标签时学习控制。
具体来说,Genie 借助大量公开的互联网视频数据集进行了训练,没有任何动作标签数据。
这本来是一个挑战,因为互联网视频通常没有关于正在执行哪个动作、应该控制图像哪一部分的标签,但 Genie 能够专门从互联网视频中学习细粒度的控制。
对于 Genie 而言,它不仅了解观察到的哪些部分通常是可控的,而且还能推断出在生成环境中一致的各种潜在动作。需要注意的是,相同的潜在动作如何在不同的 prompt 图像中产生相似的行为。
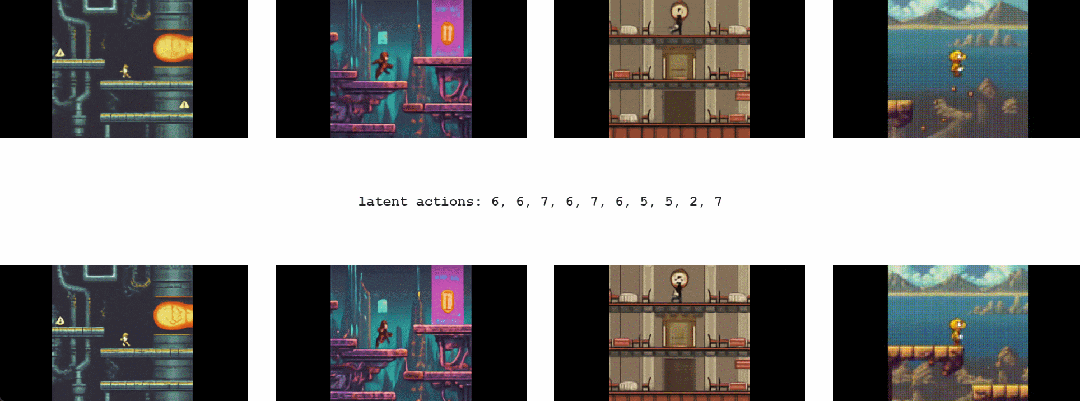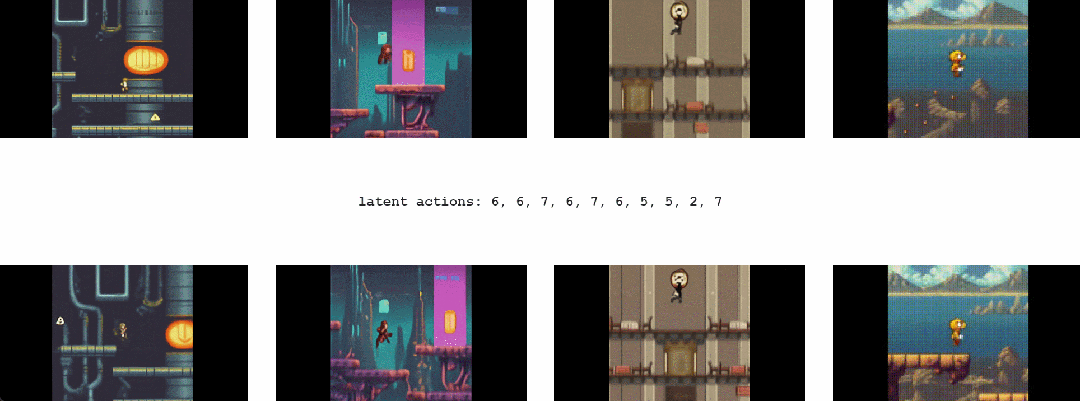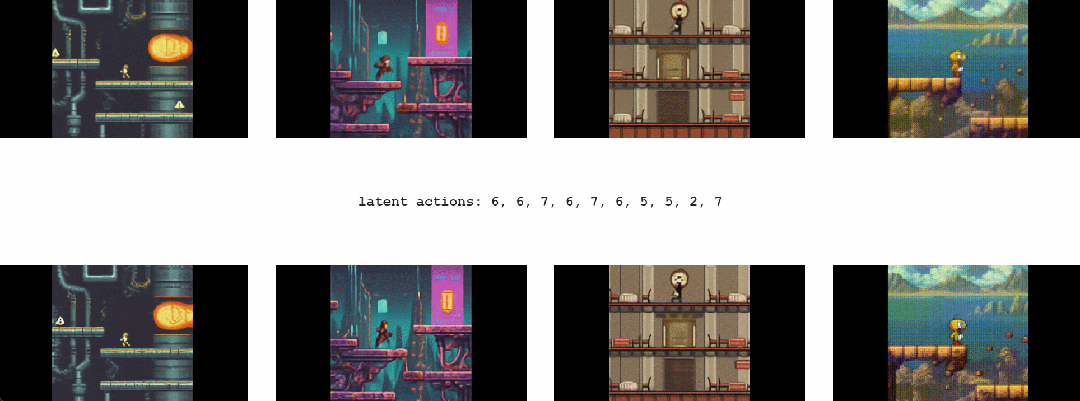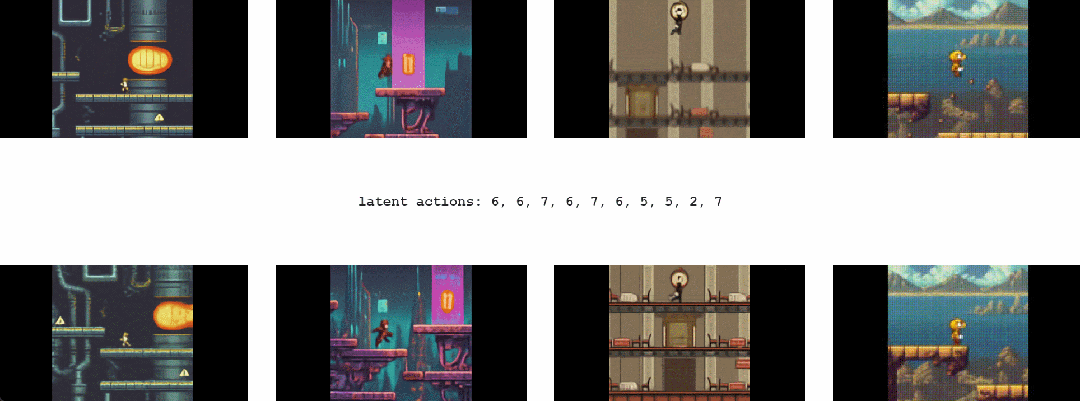
其次,Genie 可以培养下一代「创作者」(creator)。
只需要一张图像就可以创建一个全新的交互环境,这为生成和进入虚拟世界的各种新方法打开了大门。例如,我们可以使用最先进的文本生成图像模型来生成起始帧,然后与 Genie 一起生成动态交互环境。
在如下动图中,谷歌使用 Imagen2 生成了图像,再使用 Genie 将它们变为现实:

Genie 能做到的不止如此,它还可以应用到草图等人类设计相关的创作领域。

或者,应用在真实世界的图像中:

再次,谷歌认为 Genie 是实现通用智能体的基石之作。以往的研究表明,游戏环境可以成为开发 AI 智能体的有效测试平台,但常常受到可用游戏数量的限制。
现在借助 Genie,未来的 AI 智能体可以在新生成世界的无休止的 curriculum 中接受训练。谷歌提出一个概念证明,即 Genie 学到的潜在动作可以转移到真实的人类设计的环境中。
最后,谷歌表示,Genie 是一种通用方法,可以应用于多个领域,而不需要任何额外的领域知识。
尽管所用数据更多是 2D Platformer 游戏游戏和机器人视频,但该方法具备通用性,适用于任何类型的领域,并可扩展到更大的互联网数据集。
谷歌在 RT1 的无动作视频上训练了一个较小的 2.5B 模型。与 Platformers 的情况一样,具有相同潜在动作序列的轨迹通常会表现出相似的行为。
这表明 Genie 能够学习一致的动作空间,这可能适合训练机器人,打造通用化的具身智能。

技术揭秘:论文《Genie: Generative Interactive Environments》已公布
谷歌 DeepMind 已经放出了 Genie 论文。

- 论文地址:https://baitexiaoyuan.oss-cn-zhangjiakou.aliyuncs.com/itnew/qbqhxnh2vqm.pdf data-id="ld70c578-mZYO9bLG">项目主页:https://sites.google.com/view/genie-2024/home?pli=1
论文的共同一作多达 6 人,其中包括华人学者石宇歌(Yuge (Jimmy) Shi)。她目前是谷歌 DeepMind 研究科学家, 2023 年获得牛津大学机器学习博士学位。

方法介绍
Genie 架构中的多个组件基于 Vision Transformer (ViT) 构建而成。值得注意的是,由于 Transformer 的二次内存成本给视频领域带来了挑战,视频最多可以包含 ????(10^4 ) 个 token。因此,谷歌在所有模型组件中采用内存高效的 ST-transformer 架构(见图 4),以此平衡模型容量与计算约束。

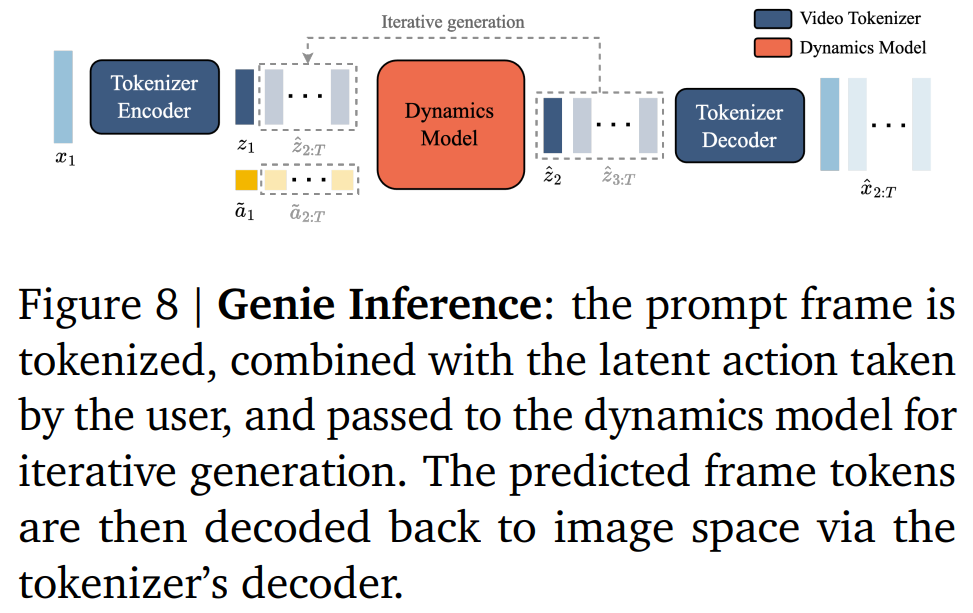
Genie 包含三个关键组件(如下图所示):
1) 潜在动作模型(Latent Action Model ,LAM),用于推理每对帧之间的潜在动作 ????;
2) 视频分词器(Tokenizer),用于将原始视频帧转换为离散 token ????;
3) 动态模型,给定潜在动作和过去帧的 token,用来预测视频的下一帧。
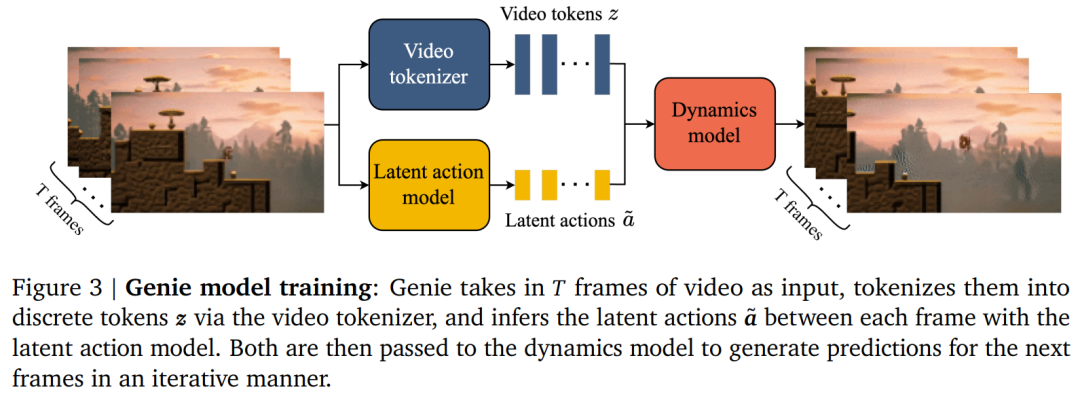
具体而言:
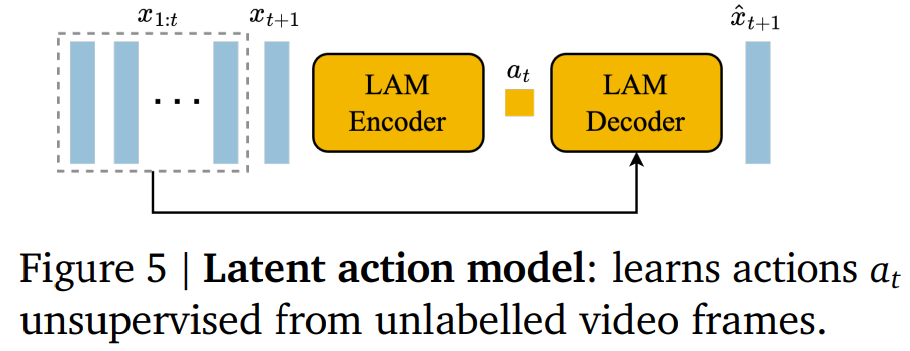
潜在动作模型:为了实现可控的视频生成,谷歌将前一帧所采取的动作作为未来帧预测的条件。然而,此类动作标签在互联网的视频中可用的很少,并且获取动作注释的成本会很高。相反,谷歌以完全无监督的方式学习潜在动作(见图 5)。
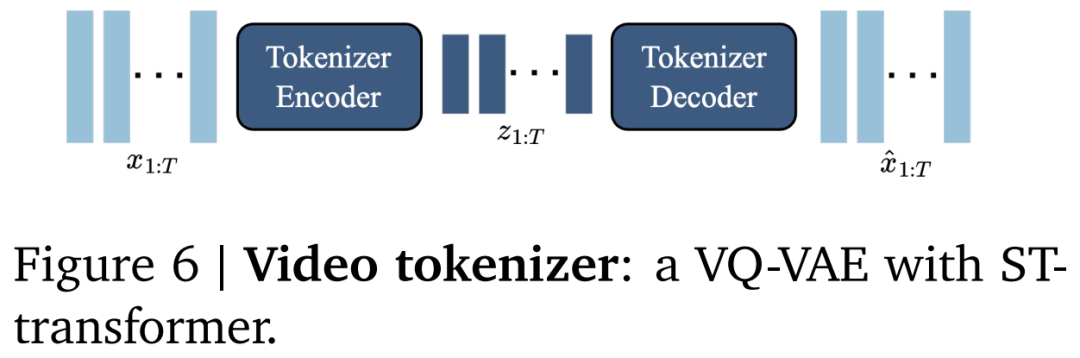
视频分词器:在之前研究的基础上,谷歌将视频压缩为离散 token,以降低维度并实现更高质量的视频生成(见图 6)。实现过程中,谷歌使用了 VQ-VAE,其将视频的 ???? 帧 作为输入,从而为每个帧生成离散表示:
作为输入,从而为每个帧生成离散表示: ,其中???? 是离散潜在空间大小。分词器在整个视频序列上使用标准的 VQ-VQAE 进行训练。
,其中???? 是离散潜在空间大小。分词器在整个视频序列上使用标准的 VQ-VQAE 进行训练。
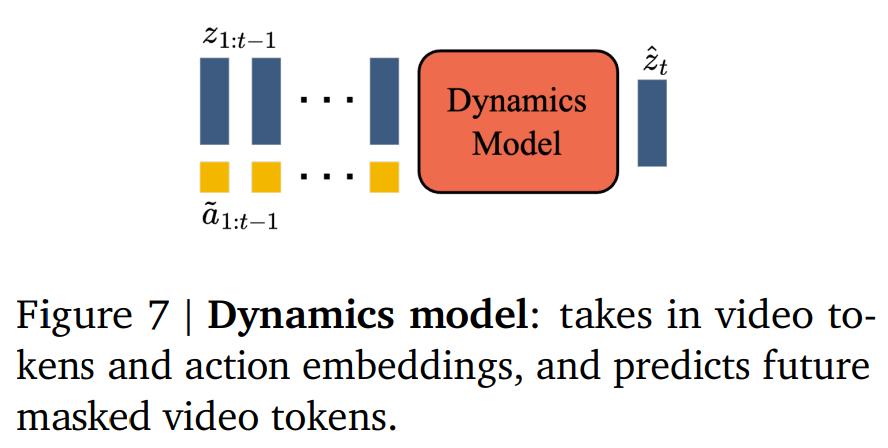
动态模型:是一个仅解码器的 MaskGIT transformer(图 7)。
Genie 的推理过程如下所示
实验结果
扩展结果
为了研究模型的扩展行为,谷歌对参数量为 2.7B 到 41M 的模型进行了实验来探讨模型大小和批大小的影响,实验结果如下图 9 所示。
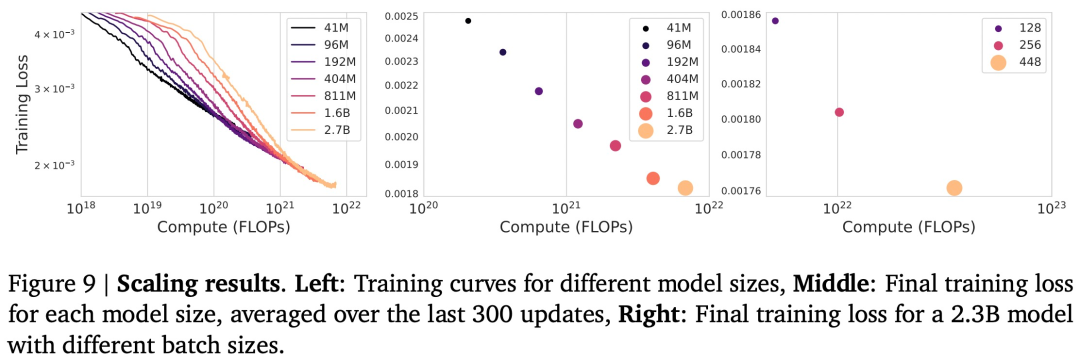
可以观察到,模型大小增加,最终训练损失会减少。这有力地表明 Genie 方法受益于扩展。同时,增加批大小也会给模型性能带来增益。
定性结果
谷歌展示了在 Platformers 数据集上训练的 Genie 11B 参数模型和在 Robotics 数据集上训练的较小模型的定性实验结果。结果表明,Genie 模型可以生成跨不同领域的高质量、可控视频。值得注意的是,谷歌仅使用分布外(OOD)图像 prompt 来定性评估其平台训练模型,这表明 Genie 方法的稳健性和大规模数据训练的价值。



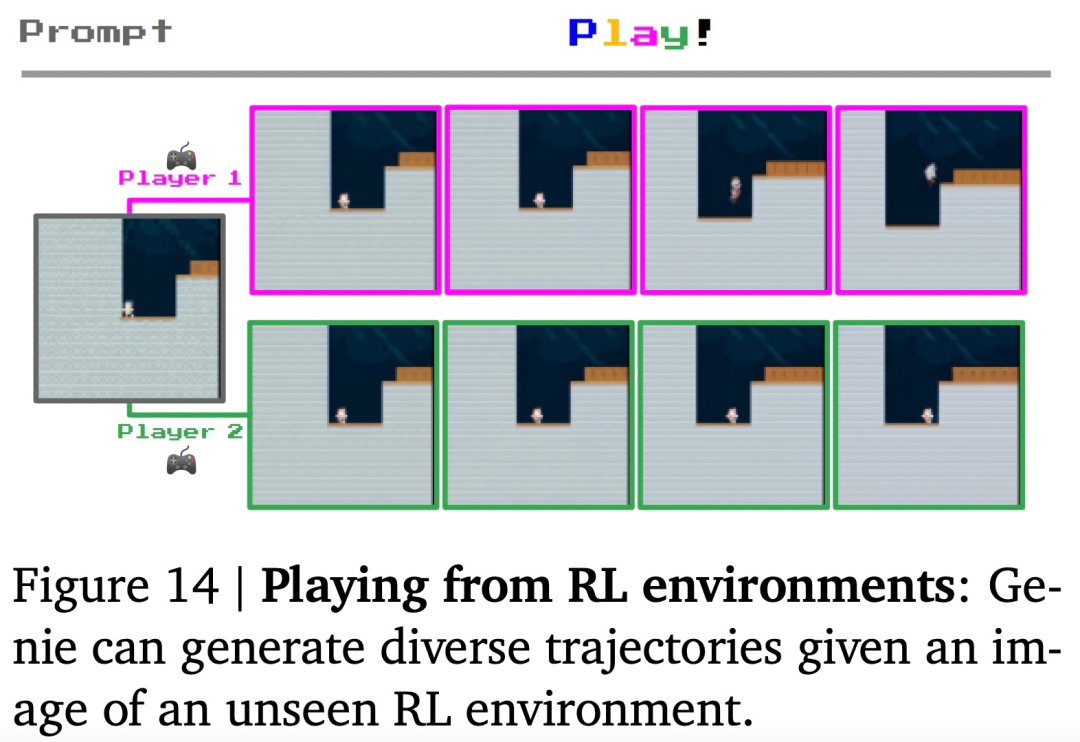
智能体训练。或许有一天,Genie 可以被用作训练多任务智能体的基础世界模型。在图 14 中,作者展示了该模型已经可以用于在给定起始帧的全新 RL 环境中生成不同的轨迹。
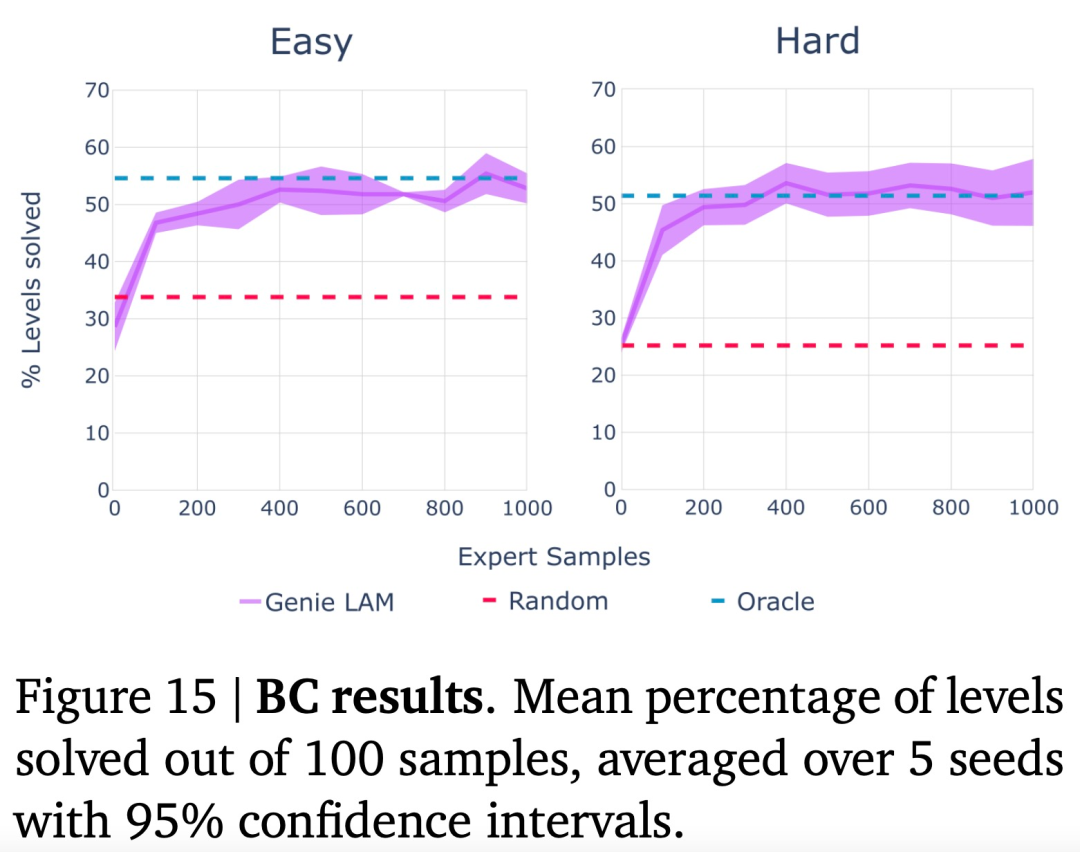
作者在程序生成的 2D 平台游戏环境 CoinRun 中进行评估,并与能够访问专家操作作为上限的预言机行为克隆 (BC) 模型进行比较。
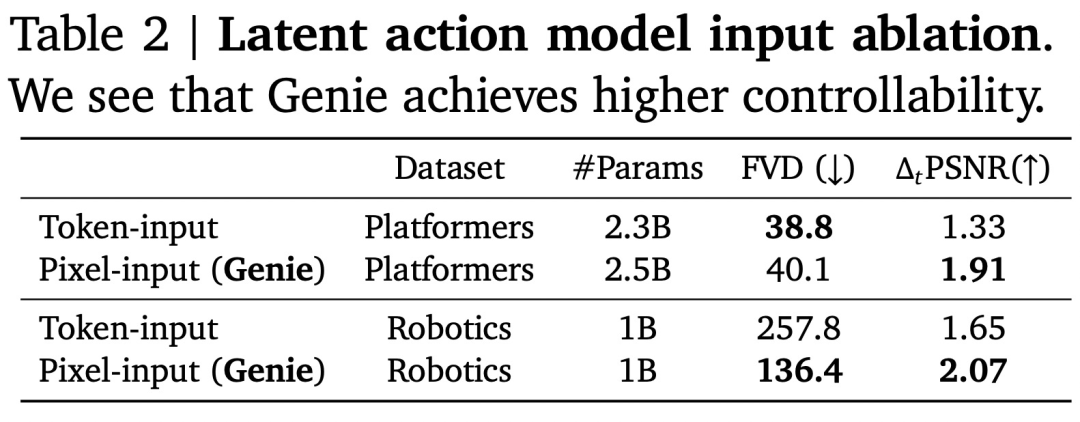
消融研究。选择在设计潜在动作模型时,作者仔细考虑了要使用的输入类型。虽然最终选择使用原始图像(像素),但作者在设计 Genie 时针对使用标记化图像的替代方案(在图 5 中用 z 替换 x)来评估这一选择。这种替代方法称为「token 输入」模型(参见表 2)。
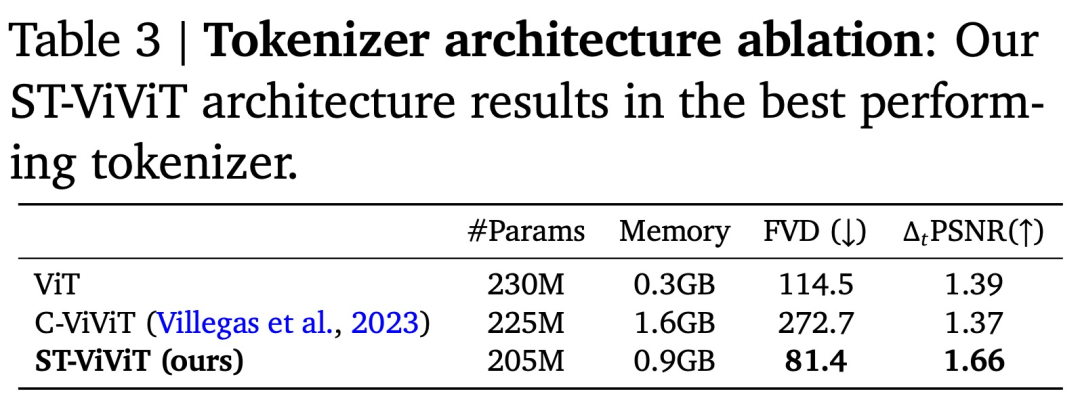
分词器架构消融。作者比较了三种分词器选择的性能,包括 1)(仅空间)ViT、2)(时空)ST-ViViT 和 3)(时空)CViViT(表 3)。

发表评论 取消回复