
mysql中适合分表的情况:1、数据量过大,正常运维影响业务访问时,例如对数据库进行备份需要大量的磁盘IO和网络IO、对一个表进行DDL修改会锁住全表、对大表进行访问与更新出现锁等待;2、随着业务发展,需要对某些字段垂直拆分;3、单表中的数据量快速增长,当性能接近瓶颈时,就需要考虑水平切分。

本教程操作环境:windows7系统、mysql8版本、Dell G3电脑。
并不是所有表都需要进行切分,主要还是看数据的增长速度。切分后会在某种程度上提升业务的复杂度,数据库除了承载数据的存储和查询外,协助业务更好的实现需求也是其重要工作之一。
不到万不得已不用轻易使用分库分表这个大招,避免"过度设计"和"过早优化"。分库分表之前,不要为分而分,先尽力去做力所能及的事情,例如:升级硬件、升级网络、读写分离、索引优化等等。当数据量达到单表的瓶颈时候,再考虑分库分表。
那么mysql中什么时候考虑分表
1、数据量过大,正常运维影响业务访问
这里说的运维,指:
对数据库备份,如果单表太大,备份时需要大量的磁盘IO和网络IO。例如1T的数据,网络传输占50MB时候,需要20000秒才能传输完毕,整个过程的风险都是比较高的
对一个很大的表进行DDL修改时,MySQL会锁住全表,这个时间会很长,这段时间业务不能访问此表,影响很大。如果使用pt-online-schema-change,使用过程中会创建触发器和影子表,也需要很长的时间。在此操作过程中,都算为风险时间。将数据表拆分,总量减少,有助于降低这个风险。
大表会经常访问与更新,就更有可能出现锁等待。将数据切分,用空间换时间,变相降低访问压力
2、随着业务发展,需要对某些字段垂直拆分
举个例子,假如项目一开始设计的用户表如下:

在项目初始阶段,这种设计是满足简单的业务需求的,也方便快速迭代开发。而当业务快速发展时,用户量从10w激增到10亿,用户非常的活跃,每次登录会更新 last_login_name 字段,使得 user 表被不断update,压力很大。而其他字段:id, name, personal_info 是不变的或很少更新的,此时在业务角度,就要将 last_login_time 拆分出去,新建一个 user_time 表。
personal_info 属性是更新和查询频率较低的,并且text字段占据了太多的空间。这时候,就要对此垂直拆分出 user_ext 表了。
3、数据量快速增长
随着业务的快速发展,单表中的数据量会持续增长,当性能接近瓶颈时,就需要考虑水平切分,做分库分表了。此时一定要选择合适的切分规则,提前预估好数据容量
业务案例分析
1、用户中心业务场景
用户中心是一个非常常见的业务,主要提供用户注册、登录、查询/修改等功能,其核心表为:
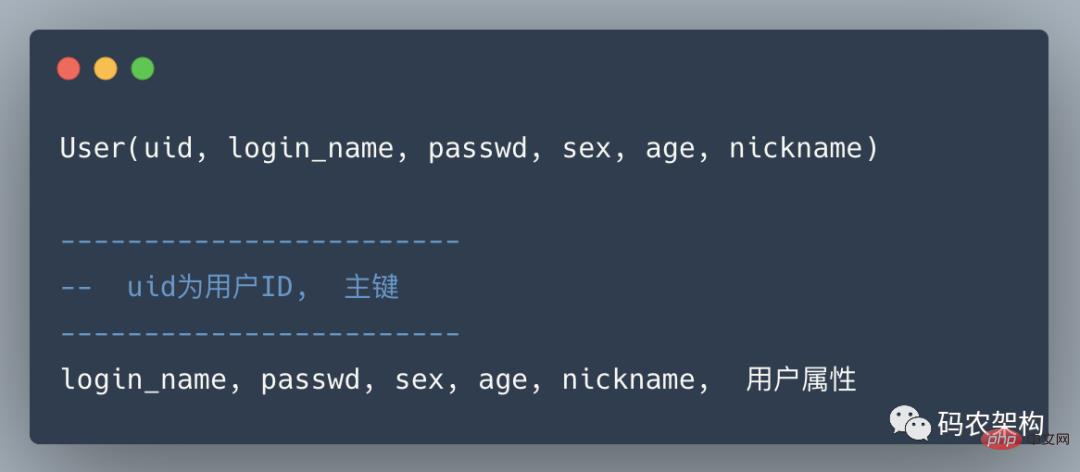
任何脱离业务的架构设计都是耍流氓,在进行分库分表前,需要对业务场景需求进行梳理:
用户侧:前台访问,访问量较大,需要保证高可用和高一致性。主要有两类需求:
用户登录:通过login_name/phone/email查询用户信息,1%请求属于这种类型
用户信息查询:登录之后,通过uid来查询用户信息,99%请求属这种类型
运营侧:后台访问,支持运营需求,按照年龄、性别、登陆时间、注册时间等进行分页的查询。是内部系统,访问量较低,对可用性、一致性的要求不高。
2、水平切分方法
当数据量越来越大时,需要对数据库进行水平切分,上文描述的切分方法有"根据数值范围"和"根据数值取模"。
"根据数值范围":以主键uid为划分依据,按uid的范围将数据水平切分到多个数据库上。例如:user-db1存储uid范围为0~1000w的数据,user-db2存储uid范围为1000w~2000wuid数据。
优点是:扩容简单,如果容量不够,只要增加新db即可。
不足是:请求量不均匀,一般新注册的用户活跃度会比较高,所以新的user-db2会比user-db1负载高,导致服务器利用率不平衡
"根据数值取模":也是以主键uid为划分依据,按uid取模的值将数据水平切分到多个数据库上。例如:user-db1存储uid取模得1的数据,user-db2存储uid取模得0的uid数据。
优点是:数据量和请求量分布均均匀
不足是:扩容麻烦,当容量不够时,新增加db,需要rehash。需要考虑对数据进行平滑的迁移。
非uid的查询方法
水平切分后,对于按uid查询的需求能很好的满足,可以直接路由到具体数据库。而按非uid的查询,例如login_name,就不知道具体该访问哪个库了,此时需要遍历所有库,性能会降低很多。
对于用户侧,可以采用"建立非uid属性到uid的映射关系"的方案;对于运营侧,可以采用"前台与后台分离"的方案。
1、建立非uid属性到uid的映射关系
映射关系
例如:login_name不能直接定位到数据库,可以建立login_name→uid的映射关系,用索引表或缓存来存储。当访问login_name时,先通过映射表查询出login_name对应的uid,再通过uid定位到具体的库。
映射表只有两列,可以承载很多数据,当数据量过大时,也可以对映射表再做水平切分。这类kv格式的索引结构,可以很好的使用cache来优化查询性能,而且映射关系不会频繁变更,缓存命中率会很高。
基因法
分库基因:假如通过uid分库,分为8个库,采用uid%8的方式进行路由,此时是由uid的最后3bit来决定这行User数据具体落到哪个库上,那么这3bit可以看为分库基因。
2、前台与后台分离
对于用户侧,主要需求是以单行查询为主,需要建立login_name/phone/email到uid的映射关系,可以解决这些字段的查询问题。
而对于运营侧,很多批量分页且条件多样的查询,这类查询计算量大,返回数据量大,对数据库的性能消耗较高。此时,如果和用户侧公用同一批服务或数据库,可能因为后台的少量请求,占用大量数据库资源,而导致用户侧访问性能降低或超时。
这类业务最好采用"前台与后台分离"的方案,运营侧后台业务抽取独立的service和db,解决和前台业务系统的耦合。由于运营侧对可用性、一致性的要求不高,可以不访问实时库,而是通过binlog异步同步数据到运营库进行访问。在数据量很大的情况下,还可以使用ES搜索引擎或Hive来满足后台复杂的查询方式。
【相关推荐:mysql视频教程】
以上就是mysql中什么时候分表的详细内容,转载自php中文网



发表评论 取消回复