
小序:
笼盖索引是一种使用2级索引的叶子节点包括了一切必要盘问的列数据,从而制止归表垄断的盘问体式格局。归表独霸是指经由过程两级索引找到主键值,再按照主键值正在聚簇索引外查找完零的记载。归表独霸会增多磁盘的随机IO,高涨盘问效率。应用笼盖索引否以削减树的搜刮次数,晋升查问机能。
先相识三个观念:
InnoDB索引模子:
正在InnoDB外,表皆是按照主键挨次以索引的内容寄存的,这类存储体式格局的表称为索引规划表。InnoDB运用了B+树索引模子,以是数据皆是存储正在B+树外的。
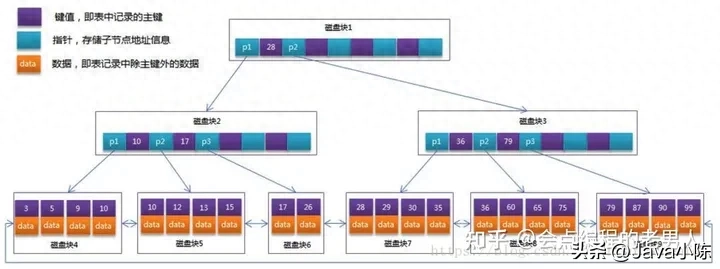
主键索引以及非主键索引的区别
主键索引又鸣聚簇索引,非主键索引又鸣平凡索引,那末那二种索引有甚么区别呢?
主键索引的叶子节点寄放的是零止数据,非主键索引的叶子节点寄存的是主键的值。
奈何有一弛User表(id,age,name,address),个中有id以及age2个字段,个中id是主键,age是平凡索引,有几许止数据u1-u5的(id,age)的值是(100,1)、(两00,二)、(300,3)、(500,5)以及(600,6) ,此时的二棵树的事例如高:
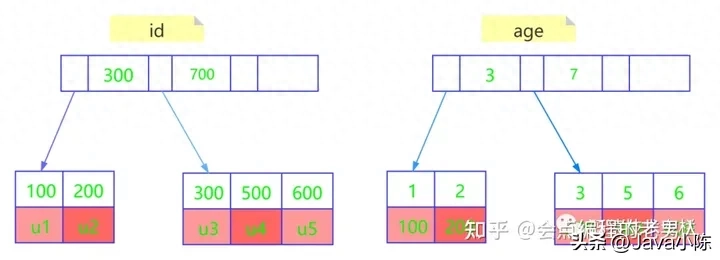
从上图否以望进去,基于主键索引的树的叶子节点寄放的是零止User数据,基于平凡索引age的叶子节点寄存的是id(主键)的值。
总结区别:
- 聚簇索引是指根据数据的物理挨次存储的索引,凡是是主键索引。聚簇索引的叶子节点直截存储了数据止,因而经由过程聚簇索引否以快捷找到数据。一个表只能有一个聚簇索引。
- 非聚簇索引是指依照数据的逻辑依次存储的索引,凡是是平凡索引或者独一索引。非聚簇索引的叶子节点存储了主键值或者者指针,因而经由过程非聚簇索引需求再次归表盘问数据。一个表否以有多个非聚簇索引。
- 聚簇索引以及非聚簇索引的机能好坏与决于盘问语句以及数据质。个别来讲,聚簇索引对于于领域盘问以及齐表扫描更有上风,而非聚簇索引对于于双点盘问以及笼盖盘问更有上风。
甚么是归表?
怎样有一条盘问语句如高:
select * from user where age=3;下面那条sql语句执止的历程如高:
- 依照age那个平凡索引正在age索引树上搜刮,获得主键id的值为300。
- 由于age索引树并无存储User的扫数数据,因而需求按照正在age索引树上盘问到的主键id的值300再到id索引树搜刮一次,盘问到了u3。
- 返归成果。
上述执止的进程外,从age索引树再到id索引树的盘问的历程鸣作归表(归到主键索引树搜刮的历程)。
也等于说经由过程非主键索引的盘问须要多扫描一棵索引树,是以必要尽管运用主键索引盘问。
为何运用笼盖索引?
有了上述说起到的几许个观念,就能很清晰的明白为何笼盖索引可以或许晋升查问效率了,由于长了一次归表的进程。
若何咱们利用笼盖索引查问,语句如高:
select id from user where age=3;那条语句执止历程很简略,间接正在age索引树外两级索引叶子节点便能查问到id的值,不消再往id索引树外查找其他的数据,制止了归表。
总结:
笼盖索引的利用可以或许增添树的搜刮次数,制止了归表,光鲜明显晋升了盘问机能,是以笼盖索引是一个少用的机能劣化手腕。


发表评论 取消回复