
1. 使用 regexp_substr() 函数
1.1 方式1
如下:
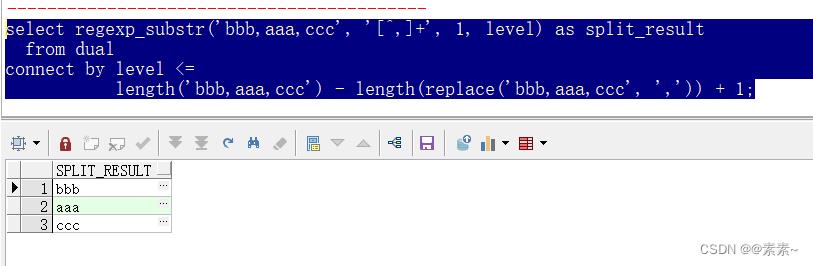
select regexp_substr('bbb,aaa,ccc', '[^,]+', 1, level) as split_result
from dual
connect by level <=
length('bbb,aaa,ccc') - length(replace('bbb,aaa,ccc', ',')) + 1;
1.2 方式2
如下:
select regexp_substr(replace('aaa;bbb;ccb', '', ';'), '[^;]+', 1, level) as split_result
from dual
connect by level <= regexp_count('aaa;bb;', ';') + 1;

或者 with 写法,如下
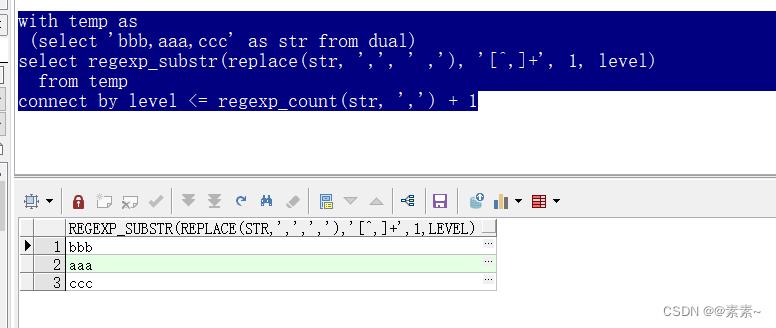
with temp as
(select 'bbb,aaa,ccc' as str from dual)
select regexp_substr(replace(str, ',', ' ,'), '[^,]+', 1, level)
from temp
connect by level <= regexp_count(str, ',') + 1
1.3 注意问题(尤其是存储过程中用到,可能会入坑)
问题情况(可能会出现空行),如下:


解决问题:
上述空行不是我们所需要的,所以排除即可,如下:
select split_result,length(split_result) from (
select regexp_substr(replace('aaa;bb;', '', ';'), '[^;]+', 1, level) as split_result
from dual
connect by level <= regexp_count('aaa;bb;', ';') + 1)
where split_result is not null;


2. 自定义函数
2.1 自定义类型 table
如下:
create or replace type result_split_list as table of varchar2(100);
2.2 自定义函数
2.2.1 自定义函数
如下:
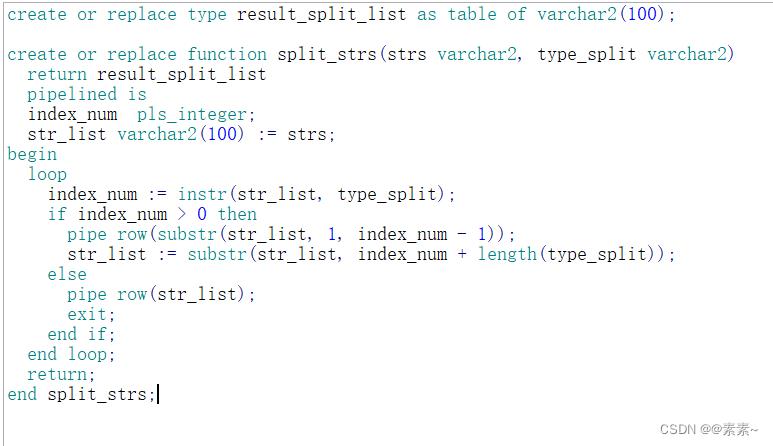
create or replace function split_strs(strs varchar2, type_split varchar2)
return result_split_list
pipelined is
index_num pls_integer;
str_list varchar2(100) := strs;
begin
loop
index_num := instr(str_list, type_split);
if index_num > 0 then
pipe row(substr(str_list, 1, index_num - 1));
str_list := substr(str_list, index_num + length(type_split));
else
pipe row(str_list);
exit;
end if;
end loop;
return;
end split_strs;
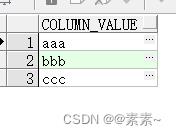
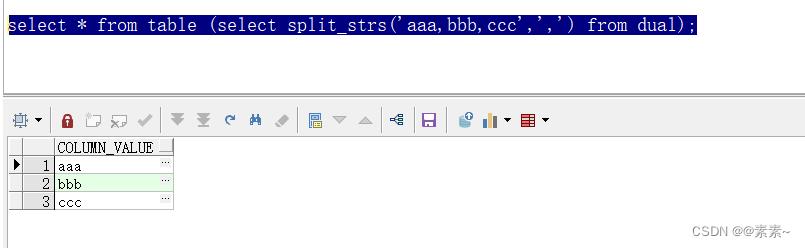
2.2.2 效果如下:
如下:

2.3 Oracle查看<Collection> 类型数据
上面的效果我们看到查看到的是<Collection> 类型,不方便查看数据,处理如下:
select * from table (select split_strs('aaa,bbb,ccc',',') from dual);
总结
到此这篇关于Oracle中分割字符串的方法的文章就介绍到这了,更多相关Oracle分割字符串内容请搜索萤火虫技术以前的文章或继续浏览下面的相关文章希望大家以后多多支持萤火虫技术!



发表评论 取消回复