
一、场景描述
查询机构下的人员,要同时查询出该机构及其所有下级机构的人员;比如查询北京市,不仅要查询出归属于北京市的人员,还要查询归属于出朝阳区、西城区、海淀区等等的人员。
对于这个需求,有以下几种解决思路:
1、之前的系统,他们的机构编码本身有关联,比如北京编码是001的话,昌平区的编码就是0012;这样的话,他们查询可以用like。这种方法的问题是like查询太慢,尤其在数据量大的时候,即使对编码加唯一索引,也只有查最根部机构时可以走索引(因为只有此时才符合最左前缀)。
2、我们的系统没有机构编码,唯一标识是雪花算法生成的19位id,没有关联;机构关系是通过一张关联表组合的起来的(适用于多业务系统,多机构树的情况)。这种情况,可以通过条件从关系表中查出所有下级机构id,然后查询时用in查询;为了方便查询,我们还建了一张机构关系冗余表。
但是这种方法也有一个问题,就是Oracle数据库in查询中元素,必须在1000以内。
二、解决方案
1、方案一:核心思路是,将集合拆分,使用or 连接。
select * from A where id in (1, 2, …, 1000) or id in (1001, …, 1999)用mybatis的话就是这样
select * from test_1
<where>
<if test="list != null and list.size > 0">
(id IN
<!-- 处理in的集合超过1000条时Oracle不支持的情况 -->
<trim suffixOverrides=" OR id IN()">
<foreach collection="list " item="Id" index="index" open="(" close=")">
<if test="index != 0">
<choose>
<when test="index % 1000 == 999">) OR id IN (</when>
<otherwise>,</otherwise>
</choose>
</if>
#{Id}
</foreach>
</trim>
)
</if>
但是这种方法不好用,实测中3万条左右的机构,用这种查询查了好久都没出来,感觉数据库都要奔溃了。
2、方案二:用子查询(临时表)+关联查询
一般来说,超过1000多条的数据,肯定不是用户填写的,而是从其他地方查询出来的;我们可以将这些数据放到一个临时表中(用子查询实现),然后用内连接关联查询。
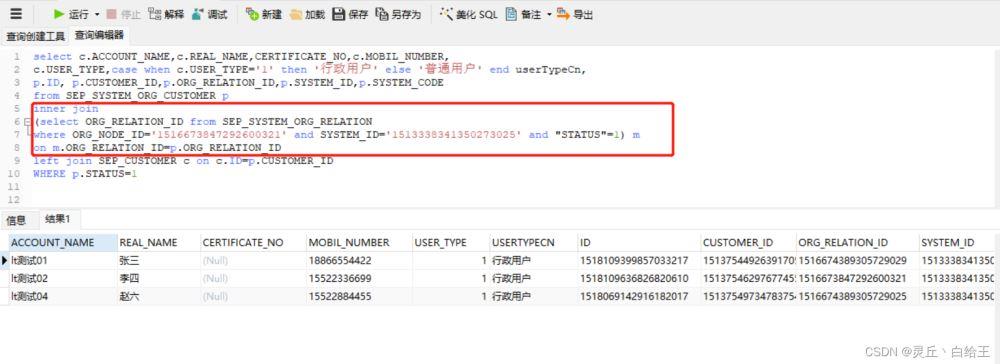
该查询中,机构关系冗余表SEP_SYSTEM_ORG_RELATION中有20多万条数据,但子查询走了我们创建的组合索引;整个查询只用了0.367秒

总结
到此这篇关于sqlin查询元素超过1000条的解决方案的文章就介绍到这了,更多相关sqlin查询元素超过1000条内容请搜索萤火虫技术以前的文章或继续浏览下面的相关文章希望大家以后多多支持萤火虫技术!



发表评论 取消回复