
一:函数介绍
np.random.permutation() 总体来说他是一个随机排列函数,就是将输入的数据进行随机排列,官方文档指出,此函数只能针对一维数据随机排列,对于多维数据只能对第一维度的数据进行随机排列。
简而言之:np.random.permutation函数的作用就是按照给定列表生成一个打乱后的随机列表
在处理数据集时,通常可以使用该函数进行打乱数据集内部顺序,并按照同样的顺序进行标签序列的打乱。
二:实例
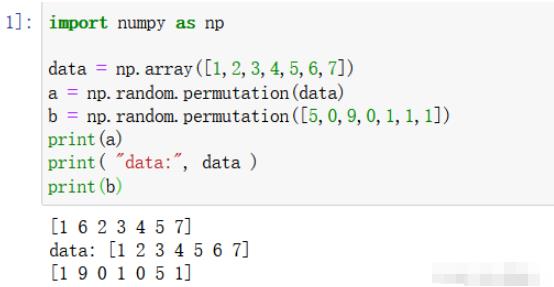
2.1 直接处理数组或列表数
import numpy as np data = np.array([1,2,3,4,5,6,7]) a = np.random.permutation(data) b = np.random.permutation([5,0,9,0,1,1,1]) print(a) print( "data:", data ) print(b)
登录后复制
2.2 间接处理:不改变原数据(对数组下标的处理)
label = np.array([1,2,3,4,5,6,7])
a = np.random.permutation(np.arange(len(label)))
print("Label[a] :" ,label[a] )登录后复制

补:一般只能用于N维数组 只能将整数标量数组转换为标量索引
why?label1[a1] label1是列表,a1是列表下标的随机排列 但是! 列表结构没有标量索引 label1[a1]报错
label1=[1,2,3,4,5,6,7]
print(len(label1))
a1 = np.random.permutation(np.arange(len(label1)))#有结果
print(a1)
print("Label1[a1] :" ,label1[a1] )#这列表结构没有标量索引 所以会报错登录后复制

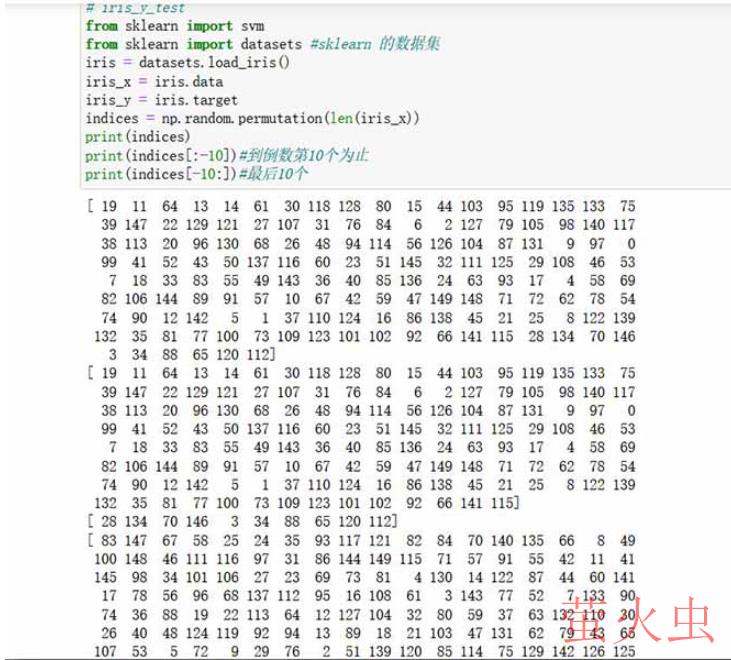
2.3 实例:鸢尾花数据中对鸢尾花的随机打乱(可以直接用)
from sklearn import svm from sklearn import datasets #sklearn 的数据集 iris = datasets.load_iris() iris_x = iris.data iris_y = iris.target indices = np.random.permutation(len(iris_x)) #此时 打乱的是数组的下标的排序 print(indices) print(indices[:-10])#到倒数第10个为止 print(indices[-10:])#最后10个 # print(type(iris_x)) <class 'numpy.ndarray'> #9:1分类 #iris_x_train = iris_x[indices[:-10]]#使用的数组打乱后的下标 #iris_y_train = iris_y[indices[:-10]] #iris_x_test= iris_x[indices[-10:]] #iris_y_test= iris_y[indices[-10:]]
登录后复制
数组下标 即标量索引的重新分布情况: 下标是0开始
以上就是python中的np.random.permutation函数怎么使用的详细内容,转载自php中文网


发表评论 取消回复