
楔子
函数是任何一门编程语言都具备的基本元素,它可以将多个要执行的操作组合起来,一个函数代表了一系列的操作。而且在调用函数时会干什么来着,没错,要创建栈帧,用于函数的执行。
PyFunctionObject
Python 一切皆对象,函数也不例外。函数在底层是通过 PyFunctionObject 结构体实现的,定义在 funcobject.h 中。
typedef struct {
/* 头部信息,无需多说 */
PyObject_HEAD
/* 函数对应的 PyCodeObject 对象
因为函数也是基于 PyCodeObject 对象构建的 */
PyObject *func_code;
/* 函数的 global 名字空间 */
PyObject *func_globals;
/* 函数参数的默认值,一个元组或者空 */
PyObject *func_defaults;
/* 只能通过关键字的方式传递的 "参数" 和 "该参数的默认值" 组成的字典
或者空 */
PyObject *func_kwdefaults;
/* 闭包 */
PyObject *func_closure;
/* 函数的 docstring */
PyObject *func_doc;
/* 函数名 */
PyObject *func_name;
/* 函数的属性字典,一般为空 */
PyObject *func_dict;
/* 弱引用列表,对函数的弱引用都会保存在里面 */
PyObject *func_weakreflist;
/* 函数所在的模块 */
PyObject *func_module;
/* 函数的类型注解 */
PyObject *func_annotations;
/* 函数的全限定名 */
PyObject *func_qualname;
/* Python 函数在底层也是某个类(PyFunction_Type)的实例对象
调用时会执行类型对象的 tp_call,在 Python 里面就是 __call__
但函数比较特殊,它创建出来就是为了调用的,所以不能走通用的 tp_call
为了优化调用效率,引入了 vectorcall */
vectorcallfunc vectorcall;
} PyFunctionObject;我们来实际获取一下这些成员,看看它们在 Python 中是如何表现的。
func_code:函数的字节码
def foo(a, b, c):
pass
code = foo.__code__
print(code) # <code object foo at ......>
print(code.co_varnames) # ('a', 'b', 'c')func_globals:global 名字空间
def foo(a, b, c):
pass
name = "古明地觉"
print(foo.__globals__) # {......, 'name': '古明地觉'}
# 拿到的其实就是外部的 global名字空间
print(foo.__globals__ is globals()) # Truefunc_defaults:函数参数的默认值
def foo(name="古明地觉", age=16):
pass
# 打印的是默认值
print(foo.__defaults__) # ('古明地觉', 16)
def bar():
pass
# 没有默认值的话,__defaults__ 为 None
print(bar.__defaults__) # Nonefunc_kwdefaults:只能通过关键字的方式传递的 "参数" 和 "该参数的默认值" 组成的字典
def foo(name="古明地觉", age=16):
pass
# 打印为 None,这是因为虽然有默认值
# 但并不要求必须通过关键字参数的方式传递
print(foo.__kwdefaults__) # None
def bar(*, name="古明地觉", age=16):
pass
print(
bar.__kwdefaults__
) # {'name': '古明地觉', 'age': 16}在前面加上一个 *,就表示后面的参数必须通过关键字的方式传递。因为如果不通过关键字参数传递的话,那么无论多少个位置参数都会被 * 接收,无论如何也不可能传递给 name、age。
我们知道如果定义了 *args,那么函数可以接收任意个位置参数,然后这些参数以元组的形式保存在 args 里面。但这里我们不需要,我们只是希望后面的参数必须通过关键字参数传递,因此前面写一个 * 即可,当然写 *args 也是可以的。
func_closure:闭包对象
def foo():
name = "古明地觉"
age = 16
def bar():
nonlocal name
nonlocal age
return bar
# 查看的是闭包里面使用的外层作用域的变量
# 所以 foo().__closure__ 是一个包含两个元素的元组
print(foo().__closure__)
"""
(<cell at 0x000001FD1D3B02B0: int object at 0x00007FFDE559D660>,
<cell at 0x000001FD1D42E310: str object at 0x000001FD1D3DA090>)
"""
print(foo().__closure__[0].cell_contents) # 16
print(foo().__closure__[1].cell_contents) # 古明地觉注意:查看闭包属性我们使用的是内层函数,不是外层的 foo。
func_doc:函数的 docstring
def foo():
"""
hi,欢迎来到我的编程教室
遇见你真好
"""
pass
print(foo.__doc__)
"""
hi,欢迎来到我的编程教室
遇见你真好
"""func_name:函数的名字
def foo(name, age):
pass
print(foo.__name__) # foo当然不光是函数,方法、类、模块都有自己的名字。
import numpy as np print(np.__name__) # numpy print(np.ndarray.__name__) # ndarray print(np.array([1, 2, 3]).transpose.__name__) # transpose
func_dict:函数的属性字典
因为函数在底层也是由一个类实例化得到的,所以它可以有自己的属性字典,只不过这个字典一般为空。
def foo(name, age):
pass
print(foo.__dict__) # {}当然啦,我们也可以整点骚操作:
def foo(name, age):
return f"name: {name}, age: {age}"
code = """
name, age = "古明地觉", 17
def foo():
return "satori"
"""
exec(code, foo.__dict__)
print(foo.name) # 古明地觉
print(foo.age) # 17
print(foo.foo()) # satori
print(foo("古明地觉", 17)) # name: 古明地觉, age: 17所以虽然叫函数,但它也是由某个类型对象实现的。
func_weakreflist:弱引用列表
Python无法获取这个属性,底层没有提供相应的接口,关于弱引用此处就不深入讨论了。
func_module:函数所在的模块
def foo(name, age):
pass
print(foo.__module__) # __main__
import pandas as pd
print(
pd.read_csv.__module__
) # pandas.io.parsers.readers
from pandas.io.parsers.readers import read_csv
print(read_csv is pd.read_csv) # True类、方法、协程也有 __module__ 属性。
func_annotations:类型注解
def foo(name: str, age: int):
pass
# Python3.5 新增的语法,但只能用于函数参数
# 而在 3.6 的时候,声明变量也可以使用这种方式
# 特别是当 IDE 无法得知返回值类型时,便可通过类型注解的方式告知 IDE
# 这样就又能使用 IDE 的智能提示了
print(foo.__annotations__)
# {'name': <class 'str'>, 'age': <class 'int'>}func_qualname:全限定名
def foo():
pass
print(foo.__name__, foo.__qualname__) # foo foo
class A:
def foo(self):
pass
print(A.foo.__name__, A.foo.__qualname__) # foo A.foo全限定名要更加地完整一些。
def foo(name, age):
pass
# <class 'function'> 就是 C 里面的 PyFunction_Type
print(foo.__class__) # <class 'function'>但是这个类底层没有暴露给我们,我们不能直接用,因为函数通过 def 创建即可,不需要通过类型对象来创建。
函数是何时创建的
前面我们说到函数在底层是由 PyFunctionObject 结构体实现的,它里面有一个 func_code 成员,指向一个 PyCodeObject 对象,函数就是根据它创建的。
因为 PyCodeObject 是对一段代码的静态表示,Python 编译器在将源代码编译之后,对里面的每一个代码块(code block)都会生成一个、并且是唯一一个 PyCodeObject 对象。该对象包含了这个代码块的一些静态信息,也就是可以从源代码当中看到的信息。
比如某个函数对应的代码块里面有一个 a = 1 这样的表达式,那么符号 a 和整数 1、以及它们之间的联系就是静态信息,而这些信息会被静态存储起来。
符号 a 被存在符号表 co_varnames 中;
整数 1 被存在常量池 co_consts 中;
这两者之间是一个赋值语句,因此会有两条指令:LOAD_CONST 和 STORE_FAST,它们存在字节码指令序列 co_code 中;
以上这些信息是编译的时候就可以得到的,因此 PyCodeObject 对象是编译之后的结果。
但是 PyFunctionObject 对象是何时产生的呢?显然它是 Python 代码在运行时动态产生的,更准确的说,是虚拟机在执行一个 def 语句的时候创建的。
当虚拟机在当前栈帧中执行字节码时发现了 def 语句,那么就代表发现了新的 PyCodeObject 对象,因为它们是可以层层嵌套的。所以虚拟机会根据这个 PyCodeObject 对象创建对应的 PyFunctionObject 对象,然后将函数名和 PyFunctionObject 对象(函数体)组成键值对放在当前的 local 空间中。
而在 PyFunctionObject 对象中,也需要拿到相关的静态信息,因此会有一个 func_code 成员指向 PyCodeObject。
除此之外,PyFunctionObject 对象中还包含了一些函数在执行时所必需的动态信息,即上下文信息。比如 func_globals,就是函数在执行时关联的 global 空间,说白了就是在局部变量找不到的时候能够找全局变量,可如果连 global 空间都没有的话,那即便想找也无从下手呀。
而 global 作用域中的符号和值必须在运行时才能确定,所以这部分必须在运行时动态创建,无法静态存储在 PyCodeObject 中,因此要根据 PyCodeObject 对象创建 PyFunctionObject 对象。总之一切的目的,都是为了更好地执行字节码。
我们举个例子:
# 虚拟机从上到下顺序执行字节码
name = "古明地觉"
age = 16
# 啪,很快啊,发现了一个 def 语句
def foo():
pass
# 出现 def,虚拟机就知道源代码进入一个新的作用域了
# 也就是遇到一个新的 PyCodeObject 对象了
# 而通过 def 可以得知这是创建函数的语句
# 所以会基于 PyCodeObject 创建 PyFunctionObject
# 因此当执行完 def 语句之后,一个函数就创建好了
# 创建完之后,会将函数名和函数体组成键值对,存放在当前的 local 空间中
print(locals()["foo"])
"""
<function foo at 0x7fdc280e6280>
"""调用的时候,会从 local 空间中取出符号 foo 对应的 PyFunctionObject 对象。然后根据这个 PyFunctionObject 对象创建 PyFrameObject 对象,也就是为函数创建一个栈帧,随后将执行权交给新创建的栈帧,并在新创建的栈帧中执行字节码。
函数是怎么创建的
通过上面的分析,我们知道了函数是虚拟机在遇到 def 语句的时候创建的,并保存在 local 空间中。当我们通过函数名()的方式调用时,会从 local 空间取出和函数名绑定的函数对象,然后执行。
那么问题来了,函数(对象)是怎么创建的呢?或者说虚拟机是如何完成 PyCodeObject 对象到 PyFunctionObject 对象之间的转变呢?显然想了解这其中的奥秘,就必须从字节码入手。
import dis
s = """
name = "satori"
def foo(a, b):
print(a, b)
return 123
foo(1, 2)
"""
dis.dis(compile(s, "<...>", "exec"))源代码很简单,定义一个变量 name 和函数 foo,然后调用函数。显然源代码在编译之后会产生两个 PyCodeObject,一个是模块的,一个是函数 foo 的,我们来看一下。
# 加载字符串常量 "satori",压入运行时栈
2 0 LOAD_CONST 0 ('satori')
# 将字符串从运行时栈弹出,并使用变量 name 绑定起来
# 也就是将 "name": "satori" 放到 local 名字空间中
2 STORE_NAME 0 (name)
# 注意这一步也是 LOAD_CONST,但它加载的是 PyCodeObject 对象
# 所以 PyCodeObject 对象本质上也是一个常量
3 4 LOAD_CONST 1 (<code object foo at 0x7fb...>)
# 加载符号 "foo"
6 LOAD_CONST 2 ('foo')
# 将符号 "foo" 和 PyCodeObject 对象从运行时栈弹出
# 然后创建 PyFunctionObject 对象,并压入运行时栈
8 MAKE_FUNCTION 0
# 将上一步创建的函数对象从运行时栈弹出,并用变量 foo 与之绑定起来
# 后续通过 foo() 即可发起函数调用
10 STORE_NAME 1 (foo)
# 函数创建完了,我们调用函数
# 通过 LOAD_NAME 将 foo 对应的函数对象(指针)压入运行时栈
6 12 LOAD_NAME 1 (foo)
# 将整数常量(参数)压入运行时栈
14 LOAD_CONST 3 (1)
16 LOAD_CONST 4 (2)
# 将栈里面的参数和函数弹出,发起调用,并将调用的结果(返回值)压入运行时栈
18 CALL_FUNCTION 2
# 从栈顶弹出返回值,然后丢弃,因为我们没有用变量接收返回值
# 如果我们用变量接收了,那么这里的指令就会从 POP_TOP 变成 STORE_NAME
20 POP_TOP
# return None
22 LOAD_CONST 5 (None)
24 RETURN_VALUE
# 以上是模块对应的字节码指令,下面是函数 foo 的字节码指令
Disassembly of <code object foo at 0x7fb......>:
# 从局部作用域中加载内置变量 print
4 0 LOAD_GLOBAL 0 (print)
# 从局部作用域中加载局部变量 a
2 LOAD_FAST 0 (a)
# 从局部作用域中加载局部变量 b
4 LOAD_FAST 1 (b)
# 从运行时栈中将参数和函数依次弹出,发起调用,也就是 print(a, b)
6 CALL_FUNCTION 2
# 从栈顶弹出返回值,然后丢弃,因为我们没有接收 print 的返回值
8 POP_TOP
# return 123
10 LOAD_CONST 1 (123)
12 RETURN_VALUE上面有一个有趣的现象,就是源代码的行号。之前看到源代码的行号都是从上往下、依次增大的,这很好理解,毕竟一条一条解释嘛。但是这里却发生了变化,先执行了第 6 行,之后再执行第 4 行。
如果是从 Python 层面的函数调用来理解的话,很容易一句话就解释了,因为函数只有在调用的时候才会执行,而调用肯定发生在创建之后。但是从字节码的角度来理解的话,我们发现函数的声明和实现是分离的,是在不同的 PyCodeObject 对象中。
确实如此,虽然函数名和函数体是一个整体,但是虚拟机在实现的时候,却在物理上将它们分离开了。
正所谓函数即变量,我们可以把函数当成普通的变量来处理。函数名就是变量名,它位于模块对应的 PyCodeObject 的符号表中;函数体就是变量指向的值,它是基于一个独立的 PyCodeObject 构建的。
换句话说,在编译时,函数体里面的代码会位于一个新的 PyCodeObject 对象当中,所以函数的声明和实现是分离的。
至此,函数的结构就已经非常清晰了。
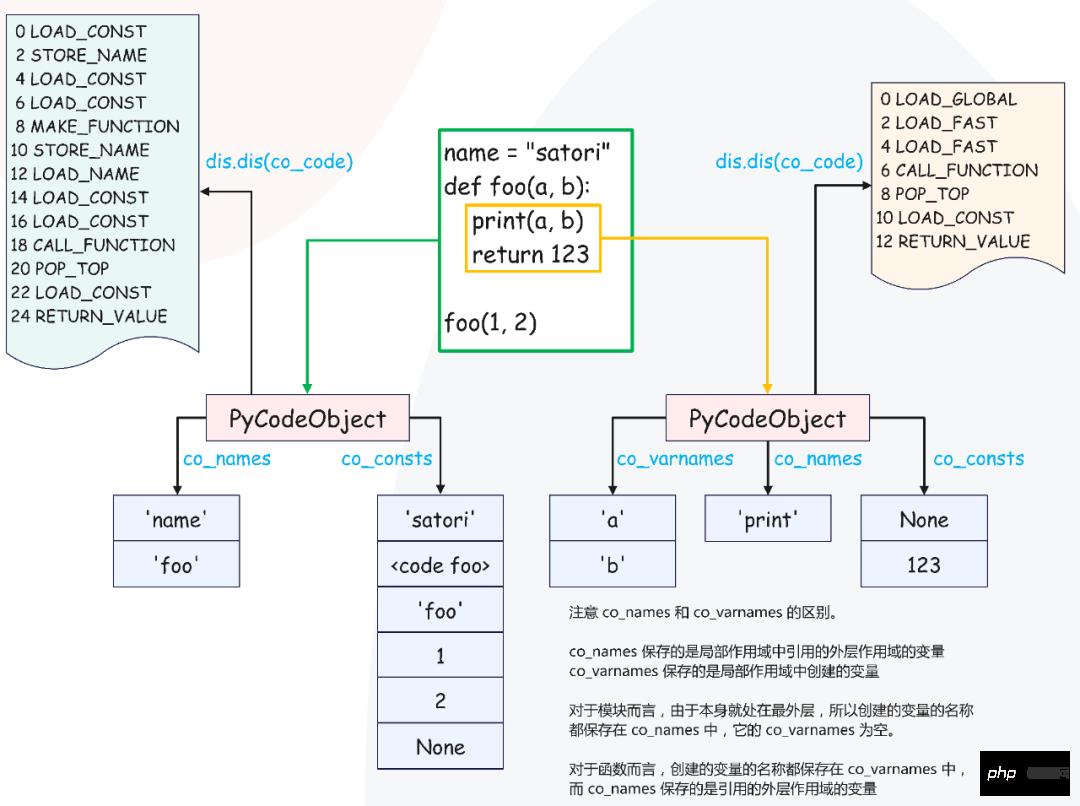
所以函数名和函数体是分离的,它们存储在不同的 PyCodeObject 对象当中。
分析完结构之后,重点就要落在 MAKE_FUNCTION 指令上了,我们说当遇到 def foo(a, b) 的时候,就知道要创建函数了。在语法上这是函数的声明语句,但从虚拟机的角度来看这其实是函数对象的创建语句。
所以下面我们就要分析一下这个指令,看看它到底是怎么将一个 PyCodeObject 对象变成一个 PyFunctionObject 对象的。
case TARGET(MAKE_FUNCTION): {
// 弹出压入运行时栈的函数名
PyObject *qualname = POP();
// 弹出对应的 PyCodeObject 对象
PyObject *codeobj = POP();
// 创建 PyFunctionObject 对象,需要三个参数
// 分别是 PyCodeObject 对象、global 名字空间、函数的全限定名
// 我们看到创建函数的时候将 global 名字空间传递了进去
// 所以现在我们应该明白为什么函数可以调用 __globals__ 了
// 当然也明白为什么函数在局部变量找不到的时候可以去找全局变量了
PyFunctionObject *func = (PyFunctionObject *)
PyFunction_NewWithQualName(codeobj, f->f_globals, qualname);
// 减少引用计数
// 如果函数创建失败会返回 NULL,跳转至 error
Py_DECREF(codeobj);
Py_DECREF(qualname);
if (func == NULL) {
goto error;
}
// 编译时能够静态检测出函数有没有设置闭包、类型注解等属性
// 比如设置了闭包,那么 oparg & 0x08 为真
// 设置了类型注解,那么 oparg & 0x04 为真
// 如果条件为真,那么进行相关属性设置
if (oparg & 0x08) {
assert(PyTuple_CheckExact(TOP()));
func ->func_closure = POP();
}
if (oparg & 0x04) {
assert(PyDict_CheckExact(TOP()));
func->func_annotations = POP();
}
if (oparg & 0x02) {
assert(PyDict_CheckExact(TOP()));
func->func_kwdefaults = POP();
}
if (oparg & 0x01) {
assert(PyTuple_CheckExact(TOP()));
func->func_defaults = POP();
}
// 将创建好的函数对象的指针压入运行时栈
// 下一个指令 STORE_NAME 会将它从运行时栈弹出
// 并用变量 foo 和它绑定起来,放入 local 空间中
PUSH((PyObject *)func);
DISPATCH();
}整个步骤很好理解,先通过 LOAD_CONST 将 PyCodeObject 对象和符号 foo 压入栈中。然后执行 MAKE_FUNCTION 的时候,将两者从栈中弹出,再加上当前栈帧对象中维护的 global 名字空间,三者作为参数传入 PyFunction_NewWithQualName 函数中,从而构建出相应的函数对象。
上面的函数比较简单,如果再加上类型注解、以及默认值,会有什么效果呢?
s = """
name = "satori"
def foo(a: int = 1, b: int = 2):
print(a, b)
foo(1, 2)
"""
import dis
dis.dis(compile(s, "func", "exec"))这里我们加上了类型注解和默认值,看看它的字节码指令会有什么变化?
0 LOAD_CONST 0 ('satori')
2 STORE_NAME 0 (name)
4 LOAD_CONST 7 ((1, 2))
6 LOAD_NAME 1 (int)
8 LOAD_NAME 1 (int)
10 LOAD_CONST 3 (('a', 'b'))
12 BUILD_CONST_KEY_MAP 2
14 LOAD_CONST 4 (<code object foo at 0x0......>)
16 LOAD_CONST 5 ('foo')
18 MAKE_FUNCTION 5 (defaults, annotations)
......
......
不难发现,在构建函数时会先将默认值以元组的形式压入运行时栈;然后再根据使用了类型注解的参数和类型构建一个字典,并将这个字典压入运行时栈。
后续创建函数的时候,会将默认值保存在 func_defaults 成员中,类型注解对应的字典会保存在 func_annotations 成员中。
def foo(a: int = 1, b: int = 2):
print(a, b)
print(foo.__defaults__)
print(foo.__annotations__)
# (1, 2)
# {'a': <class 'int'>, 'b': <class 'int'>}基于类型注解和描述符,我们便可以像静态语言一样,实现函数参数的类型约束。介绍完描述符之后,我们会举例说明。
函数的一些骚操作
我们通过一些骚操作,来更好地理解一下函数。
之前说 <class 'function'> 是函数的类型对象,而这个类底层没有暴露给我们,但是可以通过曲线救国的方式进行获取。
def f():
pass
print(type(f)) # <class 'function'>
# lambda匿名函数的类型也是 function
print(type(lambda: None)) # <class 'function'>那么下面就来创建函数:
gender = "female"
def f(name, age):
return f"name: {name}, age: {age}, gender: {gender}"
# 得到PyCodeObject对象
code = f.__code__
# 根据类function创建函数对象
# 接收三个参数: PyCodeObject对象、名字空间、函数名
new_f = type(f)(code, globals(), "根据 f 创建的 new_f")
# 打印函数名
print(new_f.__name__) # 根据 f 创建的 new_f
# 调用函数
print(
new_f("古明地觉", 16)
) # name: 古明地觉, age: 16, gender: female是不是很神奇呢?另外我们说函数在访问变量时,显然先从自身的符号表中查找,如果没有再去找全局变量。这是因为,我们在创建函数的时候将 global 名字空间传进去了,如果我们不传递呢?
gender = "female"
def f(name, age):
return f"name: {name}, age: {age}, gender: {gender}"
code = f.__code__
try:
new_f = type(f)(code, None, "根据 f 创建的 new_f")
except TypeError as e:
print(e)
"""
function() argument 'globals' must be dict, not None
"""
# 这里告诉我们 function 的第二个参数 globals 必须是一个字典
# 我们传递一个空字典
new_f1 = type(f)(code, {}, "根据 f 创建的 new_f1")
# 打印函数名
print(new_f1.__name__) # 根据 f 创建的 new_f1
# 调用函数
try:
print(new_f1("古明地觉", 16))
except NameError as e:
print(e)
"""
name 'gender' is not defined
"""
# 我们看到提示 gender 没有定义因此现在我们又从 Python 的角度理解了一遍,为什么函数能够在局部变量找不到的时候,去找全局变量。原因就在于构建函数的时候,将 global 名字空间交给了函数,使得函数可以在 global 空间进行变量查找,所以它才能够找到全局变量。而我们这里给了一个空字典,那么显然就找不到 gender 这个变量了。
gender = "female"
def f(name, age):
return f"name: {name}, age: {age}, gender: {gender}"
code = f.__code__
new_f = type(f)(code, {"gender": "少女觉"}, "根据 f 创建的 new_f")
# 我们可以手动传递一个字典进去
# 此时我们传递的字典对于函数来说就是 global 名字空间
# 所以在函数内部找不到某个变量的时候, 就会去我们指定的名字空间中查找
print(new_f("古明地觉", 16))
"""
name: 古明地觉, age: 16, gender: 少女觉
"""
# 所以此时的 gender 不再是外部的 "female"
# 而是我们指定的 "少女觉"此外我们还可以为函数指定默认值:
def f(name, age, gender):
return f"name: {name}, age: {age}, gender: {gender}"
# 必须接收一个PyTupleObject对象
f.__defaults__ = ("古明地觉", 16, "female")
print(f())
"""
name: 古明地觉, age: 16, gender: female
"""我们看到函数 f 明明接收三个参数,但是调用时不传递居然也不会报错,原因就在于我们指定了默认值。而默认值可以在定义函数的时候指定,也可以通过 __defaults__ 指定,但很明显我们应该通过前者来指定。
如果你用的是 pycharm,那么会在 f() 这个位置给你飘黄,提示你参数没有传递。但我们知道,由于使用 __defaults__ 已经设置了默认值,所以这里是不会报错的。只不过 pycharm 没有检测到,当然基本上所有的 IDE 都无法做到这一点,毕竟动态语言。
另外 __defaults__ 接收的元组里面的元素个数和参数个数不匹配怎么办?
def f(name, age, gender):
return f"name: {name}, age: {age}, gender: {gender}"
f.__defaults__ = (15, "female")
print(f("古明地恋"))
"""
name: 古明地恋, age: 15, gender: female
"""由于元组里面只有两个元素,意味着我们在调用时需要至少传递一个参数,而这个参数会赋值给 name。原因就是在设置默认值的时候是从后往前设置的,也就是 "female" 会给赋值给 gender,15 会赋值给 age。而 name 没有得到默认值,那么它就需要调用者显式传递了。
为啥 Python 在设置默认值是从后往前设置呢?如果从前往后设置的话,会出现什么后果呢?显然此时 15 会赋值给 name,"female" 会赋值给 age,那么函数就等价于如下:
def f(name=15, age="female", gender):
return f"name: {name}, age: {age}, gender: {gender}"这样的函数能够通过编译吗?显然是不行的,因为默认参数必须在非默认参数的后面。所以 Python 的这个做法是完全正确的,必须要从后往前进行设置。
另外我们知道默认值的个数是小于等于参数个数的,如果大于会怎么样呢?
def f(name, age, gender):
return f"name: {name}, age: {age}, gender: {gender}"
f.__defaults__ = ("古明地觉", "古明地恋", 15, "female")
print(f())
"""
name: 古明地恋, age: 15, gender: female
"""依旧从后往前进行设置,当所有参数都有默认值了,那么就结束了。当然,如果不使用 __defaults__,是不可能出现默认值个数大于参数个数的。
可要是 __defaults__ 指向的元组先结束,那么没有得到默认值的参数就必须由我们来传递了。
最后再来说一下如何深拷贝一个函数。首先如果是你的话,你会怎么拷贝一个函数呢?不出意外的话,你应该会使用 copy 模块。
import copy
def f(a, b):
return [a, b]
# 但是问题来了,这样能否实现深度拷贝呢?
new_f = copy.deepcopy(f)
f.__defaults__ = (2, 3)
print(new_f()) # [2, 3]修改 f 的 __defaults__,会对 new_f 产生影响,因此我们并没有实现函数的深度拷贝。事实上,copy 模块无法对函数、方法、回溯栈、栈帧、模块、文件、套接字等类型的实例实现深度拷贝。
那我们应该怎么做呢?
from types import FunctionType
def f(a, b):
return "result"
# FunctionType 就是函数的类型对象
# 它也是通过 type 得到的
new_f = FunctionType(f.__code__,
f.__globals__,
f.__name__,
f.__defaults__,
f.__closure__)
# 显然 function 还可以接收第四个参数和第五个参数
# 分别是函数的默认值和闭包
# 然后别忘记将属性字典也拷贝一份
# 由于函数的属性字典几乎用不上,这里就浅拷贝了
new_f.__dict__.update(f.__dict__)
f.__defaults__ = (2, 3)
print(f.__defaults__) # (2, 3)
print(new_f.__defaults__) # None此时修改 f 不会影响 new_f,当然在拷贝的时候也可以自定义属性。
其实上面实现的深拷贝,本质上就是定义了一个新的函数。由于是两个不同的函数,那么自然就没有联系了。
判断函数都有哪些参数
再来看看如何检测一个函数有哪些参数,首先函数的局部变量(包括参数)在编译时就已经确定,会存在符号表 co_varnames 中。
def f(a, b, /, c, d, *args, e, f, **kwargs):
g = 1
h = 2
varnames = f.__code__.co_varnames
print(varnames)
"""
('a', 'b', 'c', 'd', 'e', 'f', 'args', 'kwargs', 'g', 'h')
"""注意:在定义函数的时候,* 和 ** 最多只能出现一次。
显然 a 和 b 必须通过位置参数传递,c 和 d 可以通过位置参数和关键字参数传递,e 和 f 必须通过关键字参数传递。
而从打印的符号表来看,里面的符号是有顺序的。参数永远处于函数内部定义的局部变量的前面,比如 g 和 h 就是函数内部定义的局部变量,所以它在所有参数的后面。
而对于参数,* 和 ** 会位于最后面,其它参数位置不变。所以除了 g 和 h,最后面的就是 args 和 kwargs。
那么接下来我们就可以进行检测了。
def f(a, b, /, c, d, *args, e, f, **kwargs):
g = 1
h = 2
varnames = f.__code__.co_varnames
# 1. 寻找必须通过位置参数传递的参数
posonlyargcount = f.__code__.co_posonlyargcount
print(posonlyargcount) # 2
print(varnames[: posonlyargcount]) # ('a', 'b')
# 2. 寻找既可以通过位置参数传递、又可以通过关键字参数传递的参数
argcount = f.__code__.co_argcount
print(argcount) # 4
print(varnames[: 4]) # ('a', 'b', 'c', 'd')
print(varnames[posonlyargcount: 4]) # ('c', 'd')
# 3. 寻找必须通过关键字参数传递的参数
kwonlyargcount = f.__code__.co_kwonlyargcount
print(kwonlyargcount) # 2
print(varnames[argcount: argcount + kwonlyargcount]) # ('e', 'f')
# 4. 寻找 *args 和 **kwargs
flags = f.__code__.co_flags
# 在介绍 PyCodeObject 的时候,我们说里面有一个 co_flags 成员
# 它是函数的标识,可以对函数类型和参数进行检测
# 如果co_flags和 4 进行按位与之后为真,那么就代表有* args, 否则没有
# 如果co_flags和 8 进行按位与之后为真,那么就代表有 **kwargs, 否则没有
step = argcount + kwonlyargcount
if flags & 0x04:
print(varnames[step]) # args
step += 1
if flags & 0x08:
print(varnames[step]) # kwargs以上我们检测出了函数都有哪些参数,你也可以将其封装成一个函数,实现代码的复用。
然后需要注意一下 args 和 kwargs,打印的内容主要取决定义时使用的名字。如果定义的时候是 *ARGS 和 **KWARGS,那么这里就会打印 ARGS 和 KWARGS,只不过一般我们都叫做 *args 和 **kwargs。
但如果我们定义的时候不是 *args,只是一个 *,那么它就不是参数了。
def f(a, b, *, c):
pass
# 我们看到此时只有a、b、c
print(f.__code__.co_varnames) # ('a', 'b', 'c')
print(f.__code__.co_flags & 0x04) # 0
print(f.__code__.co_flags & 0x08) # 0
# 显然此时也都为假单独的一个 * 只是为了强制要求后面的参数必须通过关键字参数的方式传递。
函数是怎么调用的
到目前为止,我们聊了聊 Python 函数的底层实现,并且还演示了如何通过函数的类型对象自定义一个函数,以及如何获取函数的参数。虽然这在工作中没有太大意义,但是可以让我们深刻理解函数的行为。
下面我来探讨一下函数在底层是怎么调用的,但是在介绍调用之前,我们需要补充一个知识点。
def foo():
pass
print(type(foo))
print(type(sum))
"""
<class 'function'>
<class 'builtin_function_or_method'>
"""函数实际上分为两种:
如果是 Python 实现的函数,底层会对应 PyFunctionObject。其类型在 Python 里面是 <class 'function'>,在底层是 PyFunction_Type;
如果是 C 实现的函数,底层会对应 PyCFunctionObject。其类型在 Python 里面是 <class 'builtin_function_or_method'>,在底层是 PyCFunction_Type;
像内置函数、使用 C 扩展编写的函数,它们都是 PyCFunctionObject。
另外从名字上可以看出 PyCFunctionObject 不仅用于 C 实现的函数,还用于方法。关于方法,我们后续在介绍类的时候细说,这里暂时不做深入讨论。
总之对于 Python 函数和 C 函数,底层在实现的时候将两者分开了,因为 C 函数可以有更快的执行方式。
注意这里说的 C 函数,指的是 C 实现的 Python 函数。像内置函数就是 C 实现的,比如 sum、getattr 等等。
好了,下面来看函数调用的具体细节。
s = """
def foo():
a, b = 1, 2
return a + b
foo()
"""
if __name__ == '__main__':
import dis
dis.dis(compile(s, "<...>", "exec"))还是以一个简单的函数为例,看看它的字节码:
# 遇见 def 表示构建函数
# 于是加载 PyCodeObject 对象和函数名 "foo"
0 LOAD_CONST 0 (<code object foo at 0x7f...>)
2 LOAD_CONST 1 ('foo')
# 构建函数对象,压入运行时栈
4 MAKE_FUNCTION 0
# 从栈中弹出函数对象,用变量 foo 保存
6 STORE_NAME 0 (foo)
# 将变量 foo 压入运行时栈
8 LOAD_NAME 0 (foo)
# 从栈中弹出 foo,执行 foo(),也就是函数调用,这一会要剖析的重点
10 CALL_FUNCTION 0
# 从栈顶弹出返回值
12 POP_TOP
# return None
14 LOAD_CONST 2 (None)
16 RETURN_VALUE
Disassembly of <code object foo at 0x7...>:
# 函数的字节码,因为模块和函数都会对应 PyCodeObject
# 只不过后者在前者的常量池中
# 加载元组常量 (1, 2)
0 LOAD_CONST 1 ((1, 2))
# 解包,将常量压入运行时栈
2 UNPACK_SEQUENCE 2
# 再从栈中弹出,分别赋值给 a 和 b
4 STORE_FAST 0 (a)
6 STORE_FAST 1 (b)
# 加载 a 和 b
8 LOAD_FAST 0 (a)
10 LOAD_FAST 1 (b)
# 执行加法运算
12 BINARY_ADD
# 将相加之和的值返回
14 RETURN_VALUE相信现在看字节码已经不是什么问题了,然后我们看到调用函数用的是 CALL_FUNCTION 指令,那么这个指令都做了哪些事情呢?
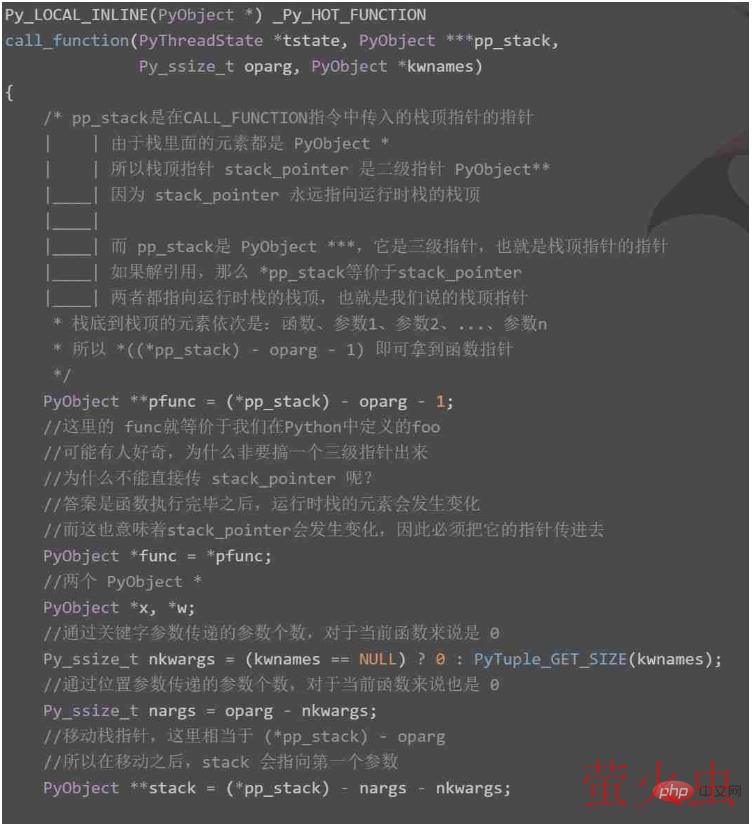
case TARGET(CALL_FUNCTION): {
PREDICTED(CALL_FUNCTION);
PyObject **sp, *res;
// 指向运行时栈的栈顶
sp = stack_pointer;
// 调用函数,将返回值赋值给 res
// tstate 表示线程状态对象
// &sp 是一个三级指针,oparg 表示指令的操作数
res = call_function(tstate, &sp, oparg, NULL);
// 函数执行完毕之后,sp 会指向运行时栈的栈顶
// 所以再将修改之后的 sp 赋值给 stack_pointer
stack_pointer = sp;
// 将 res 压入栈中:*stack_pointer++ = res
PUSH(res);
if (res == NULL) {
goto error;
}
DISPATCH();
}CALL_FUNCTION 这个指令之前提到过,但是函数的核心执行流程是在 call_function 里面,它位于 ceval.c 中,我们来看一下。

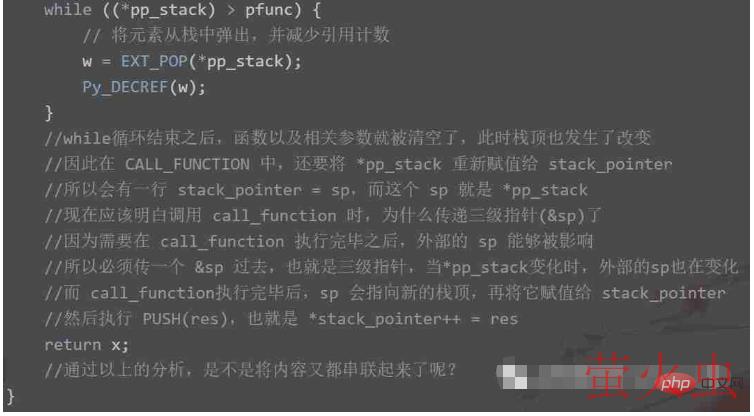
因此接下来重点就在 _PyObject_Vectorcall 函数上面,在该函数内部又会调用其它函数,最终会走到 _PyFunction_FastCallDict 这里。
//Objects/call.c
PyObject *
_PyFunction_FastCallDict(PyObject *func, PyObject *const *args, Py_ssize_t nargs,
PyObject *kwargs)
{
//获取PyCodeObject对象
PyCodeObject *co = (PyCodeObject *)PyFunction_GET_CODE(func);
//获取global名字空间
PyObject *globals = PyFunction_GET_GLOBALS(func);
//获取默认值
PyObject *argdefs = PyFunction_GET_DEFAULTS(func);
//....
//我们观察一下下面的return
//一个是function_code_fastcall,一个是最后的_PyEval_EvalCodeWithName
//从名字上能看出来function_code_fastcall是一个快分支
//但是这个快分支要求函数调用时不能传递关键字参数
if (co->co_kwonlyargcount == 0 &&
(kwargs == NULL || PyDict_GET_SIZE(kwargs) == 0) &&
(co->co_flags & ~PyCF_MASK) == (CO_OPTIMIZED | CO_NEWLOCALS | CO_NOFREE))
{
/* Fast paths */
if (argdefs == NULL && co->co_argcount == nargs) {
//function_code_fastcall里面逻辑很简单
//直接抽走当前PyFunctionObject里面PyCodeObject和global名字空间
//根据PyCodeObject对象直接为其创建一个PyFrameObject对象
//然后PyEval_EvalFrameEx执行栈帧
//也就是真正的进入了函数调用,执行函数里面的代码
return function_code_fastcall(co, args, nargs, globals);
}
else if (nargs == 0 && argdefs != NULL
&& co->co_argcount == PyTuple_GET_SIZE(argdefs)) {
/* function called with no arguments, but all parameters have
a default value: use default values as arguments .*/
args = _PyTuple_ITEMS(argdefs);
return function_code_fastcall(co, args, PyTuple_GET_SIZE(argdefs),
globals);
}
}
//适用于有关键字参数的情况
nk = (kwargs != NULL) ? PyDict_GET_SIZE(kwargs) : 0;
//.....
//调用_PyEval_EvalCodeWithName
result = _PyEval_EvalCodeWithName((PyObject*)co, globals, (PyObject *)NULL,
args, nargs,
k, k != NULL ? k + 1 : NULL, nk, 2,
d, nd, kwdefs,
closure, name, qualname);
Py_XDECREF(kwtuple);
return result;
}所以函数调用时会有两种方式:
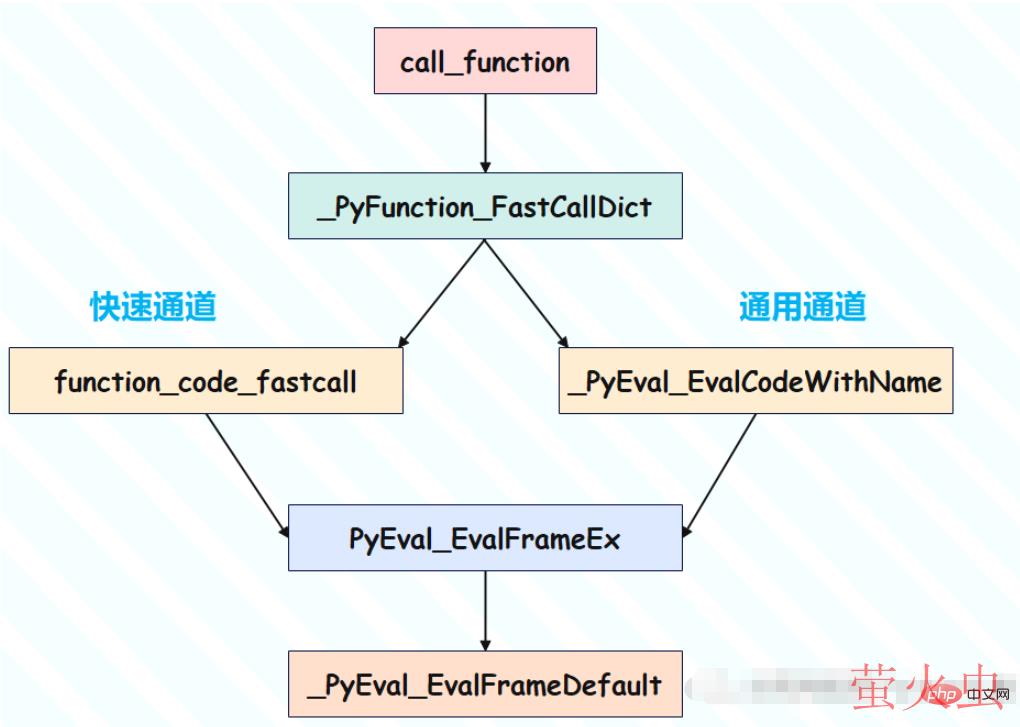
因此我们看到,总共有两条途径,分别针对有无关键字参数。但是最终殊途同归,都会走到 PyEval_EvalFrameEx 那里,然后虚拟机在新的栈帧中执行新的 PyCodeObject。
不过可能有人会好奇,我们之前说过:
PyFrameObject 是根据 PyCodeObject 创建的
PyFunctionObject 也是根据 PyCodeObject 创建的
那么 PyFrameObject 和 PyFunctionObject 之间有啥关系呢?
如果把 PyCodeObject 比喻成妹子,那么 PyFunctionObject 就是妹子的备胎,PyFrameObject 就是妹子的心上人。
其实在栈帧中执行指令时候,PyFunctionObject 的影响就已经消失了,真正对栈帧产生影响的是PyFunctionObject 里面的 PyCodeObject 对象和 global 名字空间。
也就是说,最终是 PyFrameObject 和 PyCodeObject 两者如胶似漆,跟 PyFunctionObject 之间没有关系,所以 PyFunctionObject 辛苦一场,实际上是为别人做了嫁衣。PyFunctionObject 主要是对 PyCodeObject 和 global 名字空间的一种打包和运输方式。
以上就是Python函数的实现原理是什么的详细内容,转载自php中文网


发表评论 取消回复