
学生化残差通常用于回归分析,以识别数据中潜在的异常值。异常值是与数据总体趋势显着不同的点,它可以对拟合模型产生重大影响。通过识别和分析异常值,您可以更好地了解数据中的潜在模式并提高模型的准确性。在这篇文章中,我们将仔细研究学生化残差以及如何在 python 中实现它。
什么是学生化残差?
术语“学生化残差”是指一类特定的残差,其标准差除以估计值。回归分析残差用于描述响应变量的观测值与其模型生成的预期值之间的差异。为了找到数据中可能显着影响拟合模型的异常值,采用了学生化残差。
以下公式通常用于计算学生化残差 -
studentized residual = residual / (standard deviation of residuals * (1 - hii)^(1/2))
其中“残差”是指观测到的响应值与预期响应值之间的差异,“残差标准差”是指残差标准差的估计值,“hii”是指每个数据点的杠杆因子。
用 Python 计算学生化残差
statsmodels 包可用于计算 Python 中的学生化残差。作为说明,请考虑以下内容 -
语法
OLSResults.outlier_test()
其中 OLSResults 指的是使用 statsmodels 的 ols() 方法拟合的线性模型。
df = pd.DataFrame({'rating': [95, 82, 92, 90, 97, 85, 80, 70, 82, 83],
'points': [22, 25, 17, 19, 26, 24, 9, 19, 11, 16]})
model = ols('rating ~ points', data=df).fit()
stud_res = model.outlier_test()
其中“评级”和“分数”指的是简单线性回归。
算法
导入 numpy、pandas、Statsmodel api。
创建数据集。
对数据集执行简单的线性回归模型。
计算学生化残差。
打印学生化残差。
示例
此处演示了使用 scikit−posthocs 库来运行 Dunn 的测试 -
#import necessary packages and functions
import numpy as np
import pandas as pd
import statsmodels.api as sm
from statsmodels.formula.api import ols
#create dataset
df = pd.DataFrame({'rating': [95, 82, 92, 90, 97, 85, 80, 70, 82, 83], 'points': [22, 25, 17, 19, 26, 24, 9, 19, 11, 16]})
接下来使用 statsmodels OLS 类创建线性回归模型 -
#fit simple linear regression model
model = ols('rating ~ points', data=df).fit()
使用离群值 test() 方法,可以在 DataFrame 中生成数据集中每个观察值的学生化残差 -
#calculate studentized residuals stud_res = model.outlier_test() #display studentized residuals print(stud_res)
输出
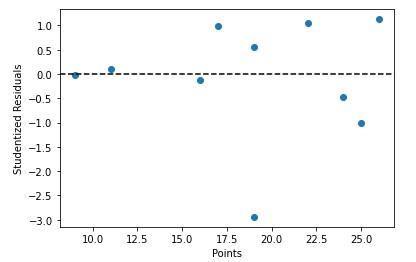
student_resid unadj_p bonf(p) 0 1.048218 0.329376 1.000000 1 -1.018535 0.342328 1.000000 2 0.994962 0.352896 1.000000 3 0.548454 0.600426 1.000000 4 1.125756 0.297380 1.000000 5 -0.465472 0.655728 1.000000 6 -0.029670 0.977158 1.000000 7 -2.940743 0.021690 0.216903 8 0.100759 0.922567 1.000000 9 -0.134123 0.897080 1.000000
我们还可以根据学生化残差快速绘制预测变量值 -
语法
x = df['points']
y = stud_res['student_resid']
plt.scatter(x, y)
plt.axhline(y=0, color='black', linestyle='--')
plt.xlabel('Points')
plt.ylabel('Studentized Residuals')
这里我们将使用 matpotlib 库来绘制颜色 = 'black' 和生活方式 = '--' 的图表
算法
导入matplotlib的pyplot库
定义预测变量值
定义学生化残差
创建预测变量与学生化残差的散点图
示例
import matplotlib.pyplot as plt
#define predictor variable values and studentized residuals
x = df['points']
y = stud_res['student_resid']
#create scatterplot of predictor variable vs. studentized residuals
plt.scatter(x, y)
plt.axhline(y=0, color='black', linestyle='--')
plt.xlabel('Points')
plt.ylabel('Studentized Residuals')
输出
结论
识别和评估可能的数据异常值。检查学生化残差可以让您找到与数据总体趋势有很大偏差的点,并探索它们影响拟合模型的原因。识别显着观测值 学生化残差可用于发现和评估有影响力的数据,这些数据对拟合模型有重大影响。寻找高杠杆点。学生化残差可用于识别高杠杆点。杠杆是衡量某个点对拟合模型影响程度的指标。总体而言,使用学生化残差有助于分析和提高回归模型的性能。