

千万级数据并发如何处理?进入学习
Redis(Remote Dictionary Server ),即远程字典服务,是一个开源的内存高速缓存数据存储服务。使用 ANSI C 语言编写,支持网络、可基于内存亦可持久化的日志型、Key-Value 数据存储,并提供多种语言的 API
Redis 是内存数据库,数据都是存储在内存中,为了避免进程退出导致数据的永久丢失,需要定期将 Redis 中的数据以某种形式(数据或命令)从内存保存到硬盘。当下次 Redis 重启时,利用持久化文件实现数据恢复。除此之外,为了进行灾难备份,可以将持久化文件拷贝到一个远程位置。Redis 的持久化机制有两种:
- RDB(Redis Data Base) 内存快照
- AOF(Append Only File) 增量日志
RDB 将当前数据保存到硬盘,AOF 则是将每次执行的写命令保存到硬盘(类似于 MySQL 的 Binlog)。AOF 持久化的实时性更好,即当进程意外退出时丢失的数据更少。
RDB 持久化
简介
RDB ( Redis Data Base) 指的是在指定的时间间隔内将内存中的数据集快照写入磁盘,RDB 是内存快照(内存数据的二进制序列化形式)的方式持久化,每次都是从 Redis 中生成一个快照进行数据的全量备份。
优点:
- 存储紧凑,节省内存空间。
- 恢复速度非常快。
- 适合全量备份、全量复制的场景,经常用于灾难恢复(对数据的完整性和一致性要求相对较低的场合)。
缺点:
- 容易丢失数据,容易丢失两次快照之间 Redis 服务器中变化的数据。
- RDB 通过 fork 子进程对内存快照进行全量备份,是一个重量级操作,频繁执行成本高。
RDB 文件结构
在默认情况下,Redis 将数据库快照保存在名字为 dump.rdb 的二进制文件中。RDB 文件结构由五个部分组成:
(1)长度为5字节的 REDIS 常量字符串。
(2)4字节的 db_version,标识 RDB 文件版本。
(3)databases:不定长度,包含零个或多个数据库,以及各数据库中的键值对数据。
(4)1字节的 EOF 常量,表示文件正文内容结束。
(5)check_sum: 8字节长的无符号整数,保存校验和。

数据结构举例,以下是数据库[0]和数据库[3]有数据的情况:

RDB 文件的创建
手动指令触发
手动触发 RDB 持久化的方式可以使用 save 命令和 bgsave 命令,这两个命令的区别如下:
save:执行 save 指令,阻塞 Redis 的其他操作,会导致 Redis 无法响应客户端请求,不建议使用。
bgsave:执行 bgsave 指令,Redis 后台创建子进程,异步进行快照的保存操作,此时 Redis 仍然能响应客户端的请求。
自动间隔性保存
在默认情况下,Redis 将数据库快照保存在名字为 dump.rdb的二进制文件中。可以对 Redis 进行设置,让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时,自动保存一次数据集。
比如说, 以下设置会让 Redis 在满足“ 60 秒内有至少有 10 个键被改动”这一条件时,自动保存一次数据集:save 60 10。
Redis 的默认配置如下,三个设置满足其一即可触发自动保存:
save 60 10000
save 300 10
save 900 1
登录后复制自动保存配置的数据结构
记录了服务器触发自动 BGSAVE 条件的saveparams属性。
lastsave 属性:记录服务器最后一次执行 SAVE 或者 BGSAVE 的时间。
dirty 属性:以及自最后一次保存 RDB 文件以来,服务器进行了多少次写入。
备份过程
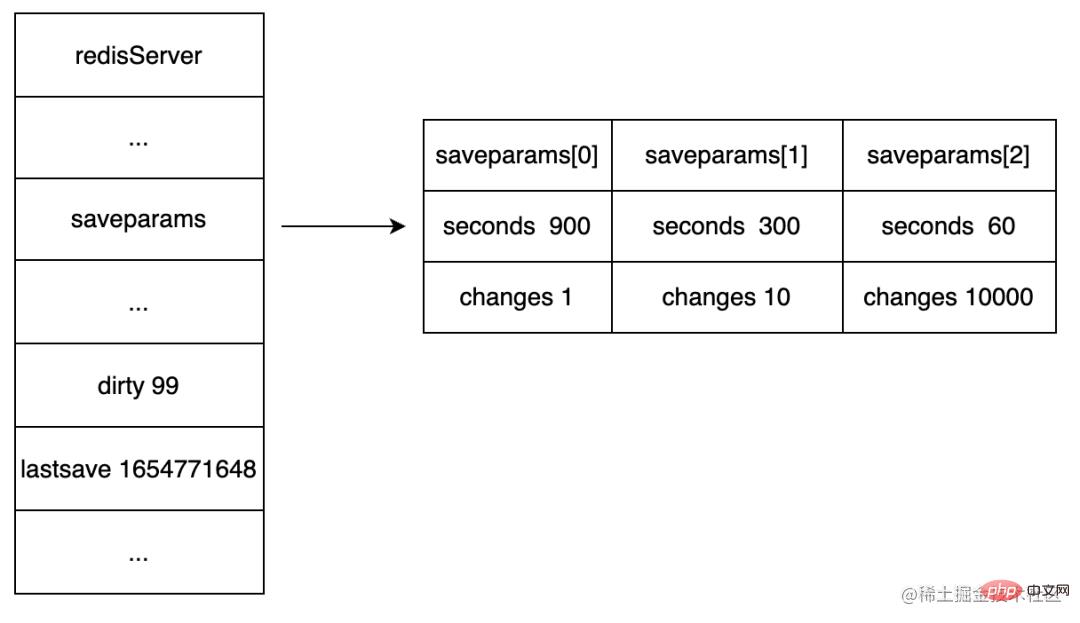
RDB 持久化方案进行备份时,Redis 会单独 fork 一个子进程来进行持久化,会将数据写入一个临时文件中,持久化完成后替换旧的 RDB 文件。在整个持久化过程中,主进程(为客户端提供服务的进程)不参与 IO 操作,这样能确保 Redis 服务的高性能,RDB 持久化机制适合对数据完整性要求不高但追求高效恢复的使用场景。下面展示 RDB 持久化流程:
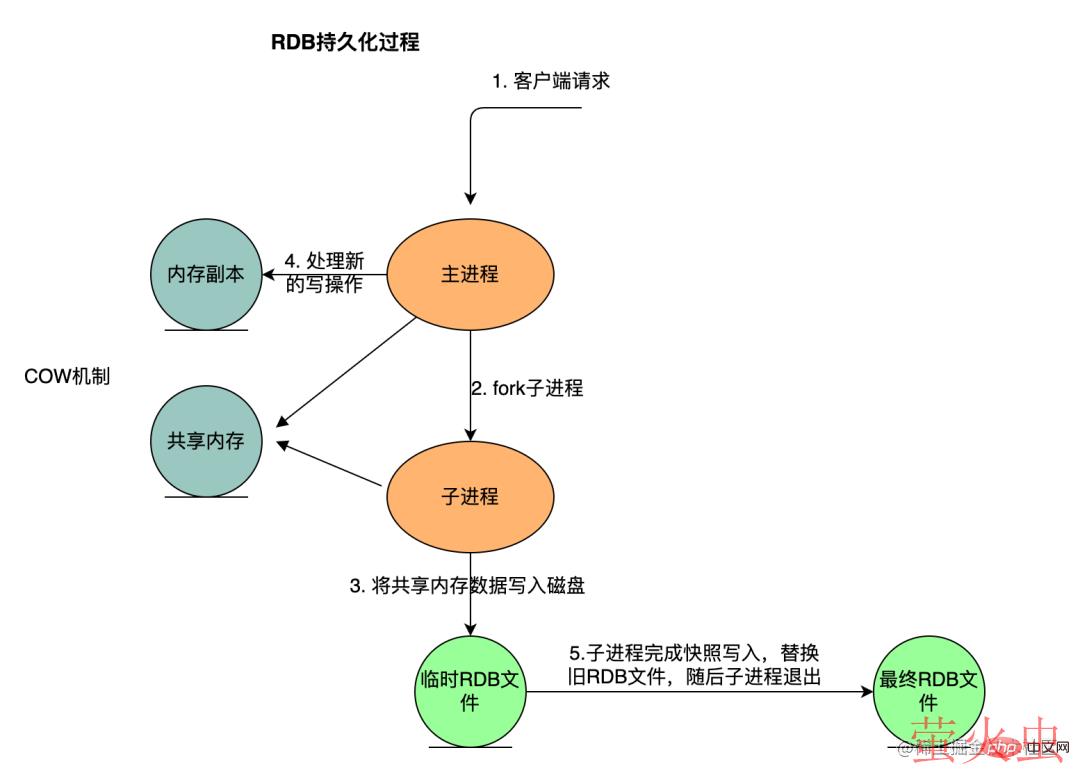
关键执行步骤如下
Redis 父进程首先判断:当前是否在执行 save,或 bgsave/bgrewriteaof 的子进程,如果在执行则 bgsave 命令直接返回。bgsave/bgrewriteaof 的子进程不能同时执行,主要是基于性能方面的考虑:两个并发的子进程同时执行大量的磁盘写操作,可能引起严重的性能问题。
- 父进程执行 fork 操作创建子进程,这个过程中父进程是阻塞的,Redis 不能执行来自客户端的任何命令。父进程 fork 后,bgsave 命令返回”Background saving started”信息并不再阻塞父进程,并可以响应其他命令。
- 子进程进程对内存数据生成快照文件。
- 父进程在此期间接收的新的写操作,使用 COW 机制写入。
- 子进程完成快照写入,替换旧 RDB 文件,随后子进程退出。
在生成 RDB 文件的步骤中,在同步到磁盘和持续写入这个过程是如何处理数据不一致的情况呢?生成快照 RDB 文件时是否会对业务产生影响?
Fork 子进程的作用
上面说到了 RDB 持久化过程中,主进程会 fork 一个子进程来负责 RDB 的备份,这里简单介绍一下 fork:
- Linux 操作系统中的程序,fork 会产生一个和父进程完全相同的子进程。子进程与父进程所有的数据均一致,但是子进程是一个全新的进程,与原进程是父子进程关系。
- 出于效率考虑,Linux 操作系统中使用 COW(Copy On Write)写时复制机制,fork 子进程一般情况下与父进程共同使用一段物理内存,只有在进程空间中的内存发生修改时,内存空间才会复制一份出来。
在 Redis 中,RDB 持久化就是充分的利用了这项技术,Redis 在持久化时调用 glibc 函数 fork 一个子进程,全权负责持久化工作,这样父进程仍然能继续给客户端提供服务。fork 的子进程初始时与父进程(Redis 的主进程)共享同一块内存;当持久化过程中,客户端的请求对内存中的数据进行修改,此时就会通过 COW (Copy On Write) 机制对数据段页面进行分离,也就是复制一块内存出来给主进程去修改。
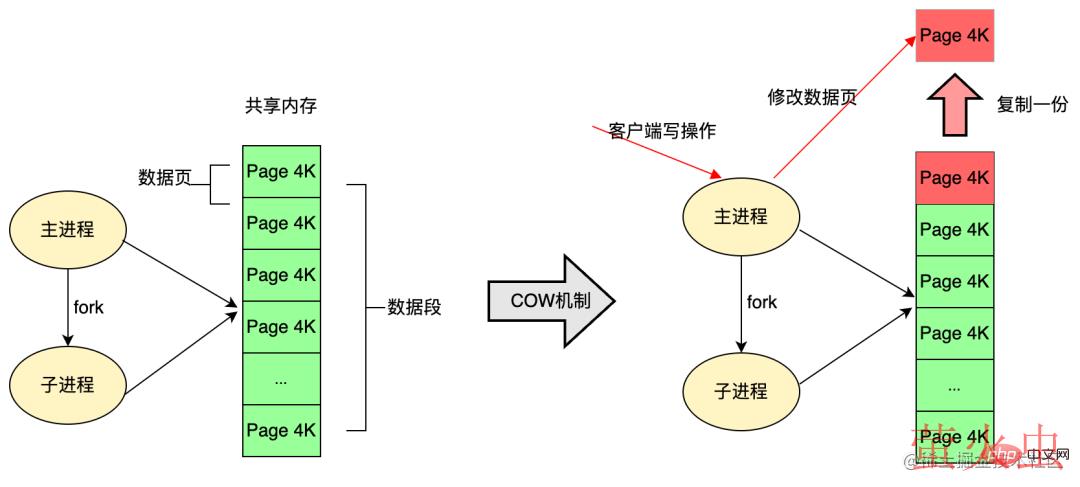
通过 fork 创建的子进程能够获得和父进程完全相同的内存空间,父进程对内存的修改对于子进程是不可见的,两者不会相互影响;
通过 fork 创建子进程时不会立刻触发大量内存的拷贝,采用的是写时拷贝 COW (Copy On Write)。内核只为新生成的子进程创建虚拟空间结构,它们来复制于父进程的虚拟究竟结构,但是不为这些段分配物理内存,它们共享父进程的物理空间,当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间;
AOF 持久化
简介
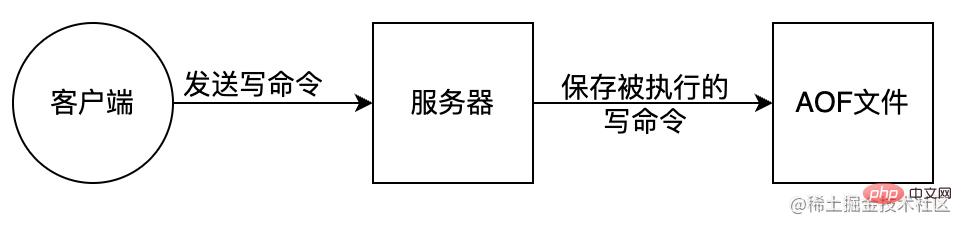
AOF (Append Only File) 是把所有对内存进行修改的指令(写操作)以独立日志文件的方式进行记录,重启时通过执行 AOF 文件中的 Redis 命令来恢复数据。类似MySql bin-log 原理。AOF 能够解决数据持久化实时性问题,是现在 Redis 持久化机制中主流的持久化方案。
优点:
- 数据的备份更加完整,丢失数据的概率更低,适合对数据完整性要求高的场景
- 日志文件可读,AOF 可操作性更强,可通过操作日志文件进行修复
缺点:
- AOF 日志记录在长期运行中逐渐庞大,恢复起来非常耗时,需要定期对 AOF 日志进行瘦身处理
- 恢复备份速度比较慢
- 同步写操作频繁会带来性能压力
AOF 文件内容
被写入 AOF 文件的所有命令都是以 RESP 格式保存的,是纯文本格式保存在 AOF 文件中。
Redis 客户端和服务端之间使用一种名为
RESP(REdis Serialization Protocol)的二进制安全文本协议进行通信。
下面以一个简单的 SET 命令进行举例:
redis> SET mykey "hello"
//客户端命令OK
登录后复制客户端封装为以下格式(每行用 \r\n分隔)
*3$3SET$5mykey$5hello
登录后复制AOF 文件中记录的文本内容如下
*2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n
//多出一个SELECT 0 命令,用于指定数据库,为系统自动添加
*3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$5\r\nhello\r\n
登录后复制AOF 持久化实现
AOF 持久化方案进行备份时,客户端所有请求的写命令都会被追加到 AOF 缓冲区中,缓冲区中的数据会根据 Redis 配置文件中配置的同步策略来同步到磁盘上的 AOF 文件中,追加保存每次写的操作到文件末尾。同时当 AOF 的文件达到重写策略配置的阈值时,Redis 会对 AOF 日志文件进行重写,给 AOF 日志文件瘦身。Redis 服务重启的时候,通过加载 AOF 日志文件来恢复数据。
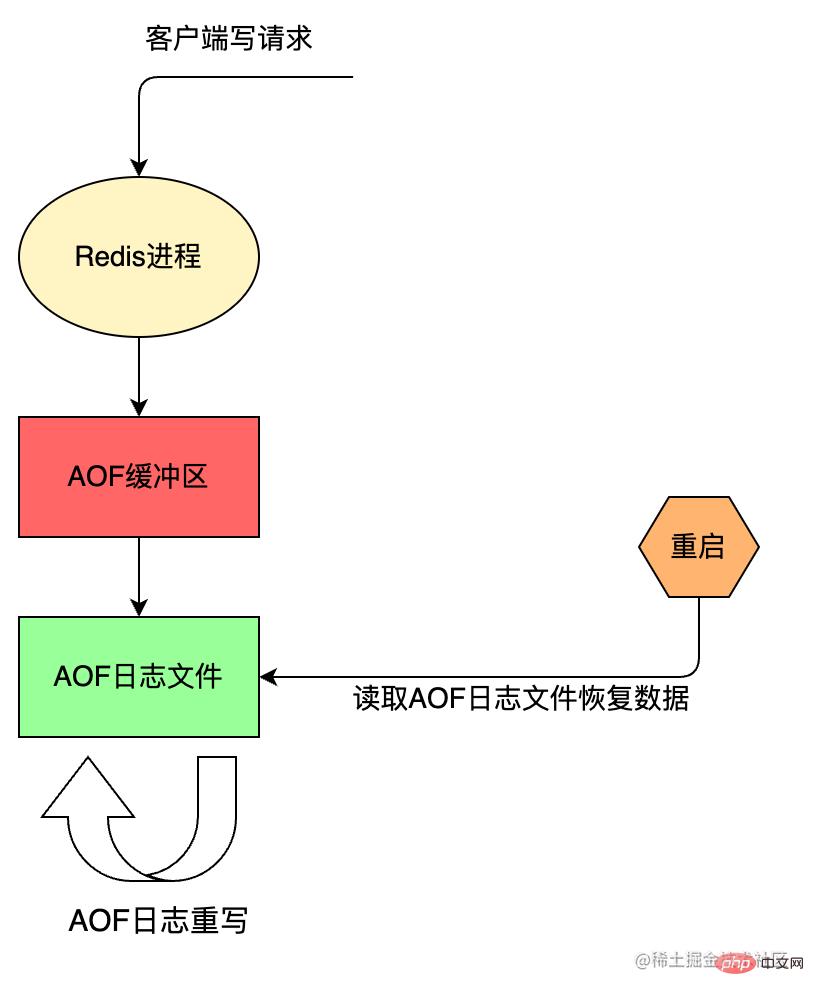
AOF 的执行流程包括:
命令追加(append)
Redis 先将写命令追加到缓冲区 aof_buf,而不是直接写入文件,主要是为了避免每次有写命令都直接写入硬盘,导致硬盘 IO 成为 Redis 负载的瓶颈。
struct redisServer {
//其他域... sds aof_buf; // sds类似于Java中的String //其他域...}
登录后复制文件写入(write)和文件同步(sync)
根据不同的同步策略将 aof_buf 中的内容同步到硬盘;
Linux 操作系统中为了提升性能,使用了页缓存(page cache)。当我们将 aof_buf 的内容写到磁盘上时,此时数据并没有真正的落盘,而是在 page cache 中,为了将 page cache 中的数据真正落盘,需要执行 fsync / fdatasync 命令来强制刷盘。这边的文件同步做的就是刷盘操作,或者叫文件刷盘可能更容易理解一些。
AOF 缓存区的同步文件策略由参数 appendfsync 控制,有三种同步策略,各个值的含义如下:
always:命令写入 aof_buf 后立即调用系统 write 操作和系统 fsync 操作同步到 AOF 文件,fsync 完成后线程返回。这种情况下,每次有写命令都要同步到 AOF 文件,硬盘 IO 成为性能瓶颈,Redis 只能支持大约几百TPS写入,严重降低了 Redis 的性能;即便是使用固态硬盘(SSD),每秒大约也只能处理几万个命令,而且会大大降低 SSD 的寿命。可靠性较高,数据基本不丢失。
no:命令写入 aof_buf 后调用系统 write 操作,不对 AOF 文件做 fsync 同步;同步由操作系统负责,通常同步周期为30秒。这种情况下,文件同步的时间不可控,且缓冲区中堆积的数据会很多,数据安全性无法保证。
everysec:命令写入 aof_buf 后调用系统 write 操作,write 完成后线程返回;fsync 同步文件操作由专门的线程每秒调用一次。everysec 是前述两种策略的折中,是性能和数据安全性的平衡,因此是 Redis 的默认配置,也是我们推荐的配置。
文件重写(rewrite)
定期重写 AOF 文件,达到压缩的目的。
AOF 重写是 AOF 持久化的一个机制,用来压缩 AOF 文件,通过 fork 一个子进程,重新写一个新的 AOF 文件,该次重写不是读取旧的 AOF 文件进行复制,而是读取内存中的Redis数据库,重写一份 AOF 文件,有点类似于 RDB 的快照方式。
文件重写之所以能够压缩 AOF 文件,原因在于:
- 过期的数据不再写入文件
- 无效的命令不再写入文件:如有些数据被重复设值(set mykey v1, set mykey v2)、有些数据被删除了(sadd myset v1, del myset)等等
- 多条命令可以合并为一个:如 sadd myset v1, sadd myset v2, sadd myset v3 可以合并为 sadd myset v1 v2 v3。不过为了防止单条命令过大造成客户端缓冲区溢出,对于 list、set、hash、zset类型的 key,并不一定只使用一条命令;而是以某个常量为界将命令拆分为多条。这个常量在 redis.h/REDIS_AOF_REWRITE_ITEMS_PER_CMD 中定义,不可更改,2.9版本中值是64。
AOF 重写
前面提到 AOF 的缺点时,说过 AOF 属于日志追加的形式来存储 Redis 的写指令,这会导致大量冗余的指令存储,从而使得 AOF 日志文件非常庞大,比如同一个 key 被写了 10000 次,最后却被删除了,这种情况不仅占内存,也会导致恢复的时候非常缓慢,因此 Redis 提供重写机制来解决这个问题。Redis 的 AOF 持久化机制执行重写后,保存的只是恢复数据的最小指令集,我们如果想手动触发可以使用如下指令:
bgrewriteaof
登录后复制文件重写时机
相关参数:
- aof_current_size:表示当前 AOF 文件空间
- aof_base_size:表示上一次重写后 AOF 文件空间
- auto-aof-rewrite-min-size: 表示运行 AOF 重写时文件的最小体积,默认为64MB
- auto-aof-rewrite-percentage: 表示当前 AOF 重写时文件空间(aof_current_size)超过上一次重写后 AOF 文件空间(aof_base_size)的比值多少后会重写。
同时满足下面两个条件,则触发 AOF 重写机制:
- aof_current_size 大于 auto-aof-rewrite-min-size
- 当前 AOF 相比上一次 AOF 的增长率:(aof_current_size - aof_base_size)/aof_base_size 大于或等于 auto-aof-rewrite-percentage
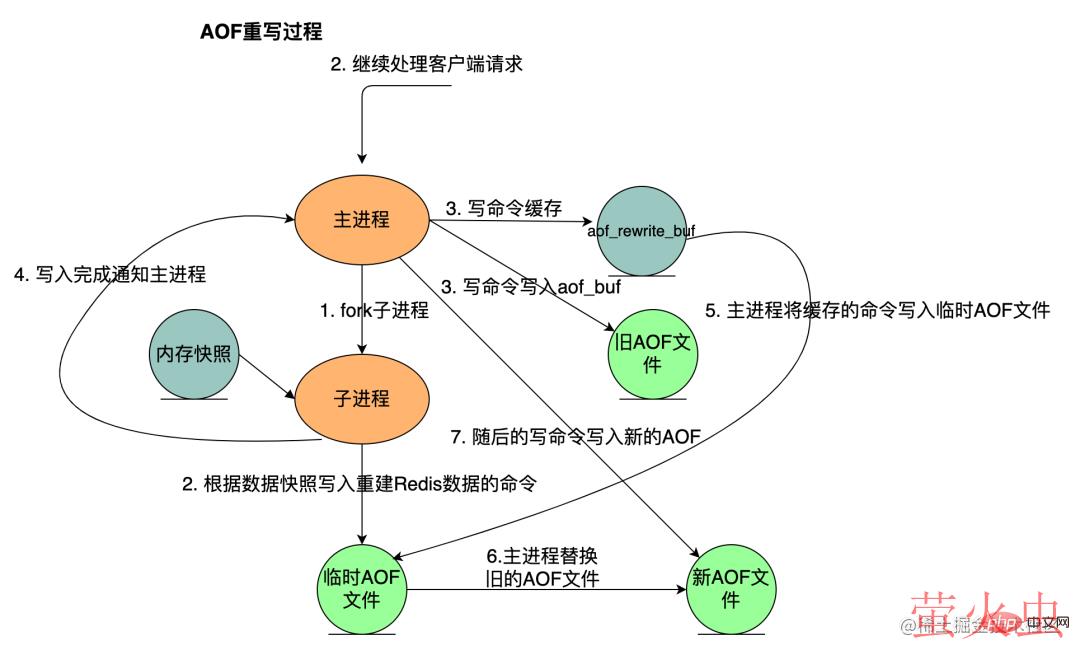
AOF 重写流程如下:
bgrewriteaof 触发重写,判断是否存在 bgsave 或者 bgrewriteaof 正在执行,存在则等待其执行结束再执行
- 主进程 fork 子进程,防止主进程阻塞无法提供服务,类似 RDB
子进程遍历 Redis 内存快照中数据写入临时 AOF 文件,同时会将新的写指令写入 aof_buf 和 aof_rewrite_buf 两个重写缓冲区,前者是为了写回旧的 AOF 文件,后者是为了后续刷新到临时 AOF 文件中,防止快照内存遍历时新的写入操作丢失
子进程结束临时 AOF 文件写入后,通知主进程
主进程会将上面 3 中的 aof_rewirte_buf 缓冲区中的数据写入到子进程生成的临时 AOF 文件中
- 主进程使用临时 AOF 文件替换旧 AOF 文件,完成整个重写过程。
在实际中,为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序会检查集合元素数量是否超过 REDIS_AOF_REWRITE_ITEMS_PER_CMD 常量的值,如果超过了,则会使用多个命令来记录,而不单单使用一条命令。
Redis 2.9版本中该常量为64,如果一个命令的集合键包含超过了64个元素,重写程序会拆成多个命令。

AOF重写是一个有歧义的名字,该功能是通过直接读取数据库的键值对实现的,程序无需对现有AOF文件进行任何读入、分析或者写入操作。
思考
AOF 与 WAL
Redis 为什么考虑使用 AOF 而不是 WAL 呢?
很多数据库都是采用的 Write Ahead Log(WAL)写前日志,其特点就是先把修改的数据记录到日志中,再进行写数据的提交,可以方便通过日志进行数据恢复。
但是 Redis 采用的却是 AOF(Append Only File)写后日志,特点就是先执行写命令,把数据写入内存中,再记录日志。
如果先让系统执行命令,只有命令能执行成功,才会被记录到日志中。因此,Redis 使用写后日志这种形式,可以避免出现记录错误命令的情况。
另外还有一个原因就是:AOF 是在命令执行后才记录日志,所以不会阻塞当前的写操作。
AOF 和 RDB 之间的相互作用
在版本号大于等于2.4的 Redis 中,BGSAVE 执行的过程中,不可以执行 BGREWRITEAOF。反过来说,在 BGREWRITEAOF 执行的过程中,也不可以执行 BGSAVE。这可以防止两个 Redis 后台进程同时对磁盘进行大量的 I/O 操作。
如果 BGSAVE 正在执行,并且用户显示地调用 BGREWRITEAOF 命令,那么服务器将向用户回复一个 OK 状态,并告知用户,BGREWRITEAOF 已经被预定执行:一旦 BGSAVE 执行完毕 BGREWRITEAOF 就会正式开始。
当 Redis 启动时,如果 RDB 持久化和 AOF 持久化都被打开了,那么程序会优先使用 AOF 文件来恢复数据集,因为 AOF 文件所保存的数据通常是最完整的。
混合持久化
Redis4.0 后大部分的使用场景都不会单独使用 RDB 或者 AOF 来做持久化机制,而是兼顾二者的优势混合使用。其原因是 RDB 虽然快,但是会丢失比较多的数据,不能保证数据完整性;AOF 虽然能尽可能保证数据完整性,但是性能确实是一个诟病,比如重放恢复数据。
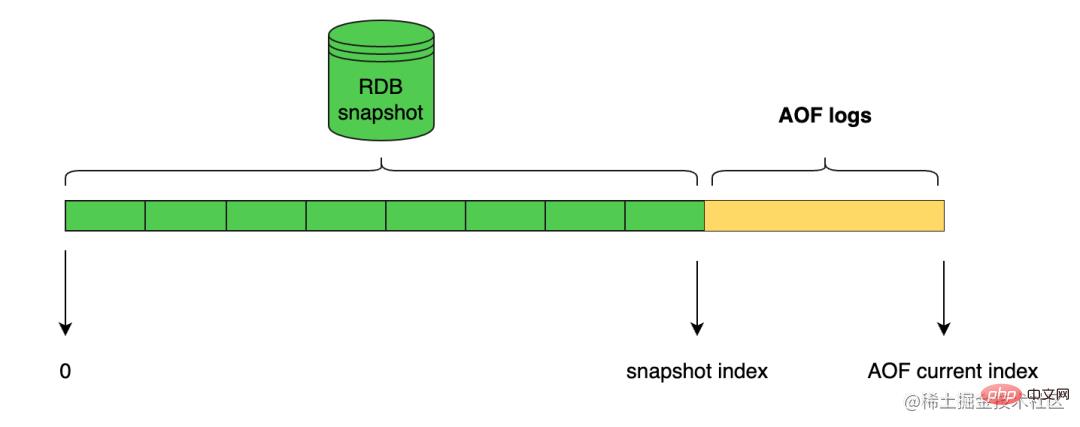
Redis从4.0版本开始引入 RDB-AOF 混合持久化模式,这种模式是基于 AOF 持久化模式构建而来的,混合持久化通过 aof-use-rdb-preamble yes 开启。
那么 Redis 服务器在执行 AOF 重写操作时,就会像执行 BGSAVE 命令那样,根据数据库当前的状态生成出相应的 RDB 数据,并将这些数据写入新建的 AOF 文件中,至于那些在 AOF 重写开始之后执行的 Redis 命令,则会继续以协议文本的方式追加到新 AOF 文件的末尾,即已有的 RDB 数据的后面。
换句话说,在开启了 RDB-AOF 混合持久化功能之后,服务器生成的 AOF 文件将由两个部分组成,其中位于 AOF 文件开头的是 RDB 格式的数据,而跟在 RDB 数据后面的则是 AOF 格式的数据。
当一个支持 RDB-AOF 混合持久化模式的 Redis 服务器启动并载入 AOF 文件时,它会检查 AOF 文件的开头是否包含了 RDB 格式的内容。
- 如果包含,那么服务器就会先载入开头的 RDB 数据,然后再载入之后的 AOF 数据。
- 如果 AOF 文件只包含 AOF 数据,那么服务器将直接载入 AOF 数据。
其日志文件结构如下:
总结
最后来总结这两者,到底用哪个更好呢?
- 推荐是两者均开启。
- 如果对数据不敏感,可以选单独用 RDB。
- 如果只是做纯内存缓存,可以都不用。
以上就是Redis持久化策略浅析的详细内容,转载自php中文网



发表评论 取消回复