

redis的数据结构:String(字符串)、List(列表)、hash(哈希)、Set(集合)、Shorted Set(有序集合)
底层数据结构:简单动态字符串、双向链表、压缩列表、哈希表、跳表、整数数组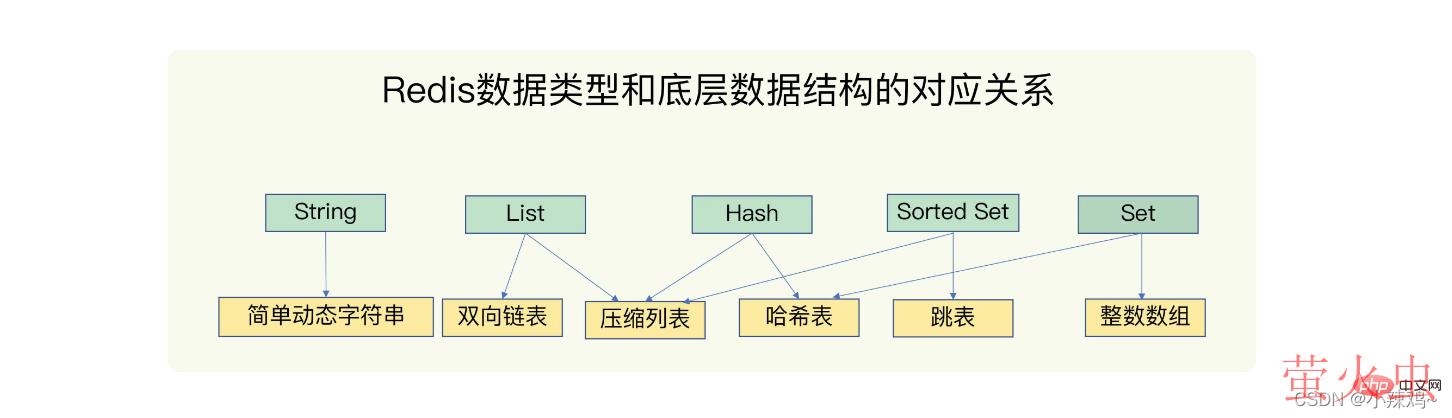
1.哈希表:一个哈希表其实就是一个数组,数组中的每一个元素称为一个哈希桶。
哈希冲突和rehash可能会带来操作阻塞。
redis解决哈希冲突的方法是链式哈希,而rehash是增加现有hash桶的数量。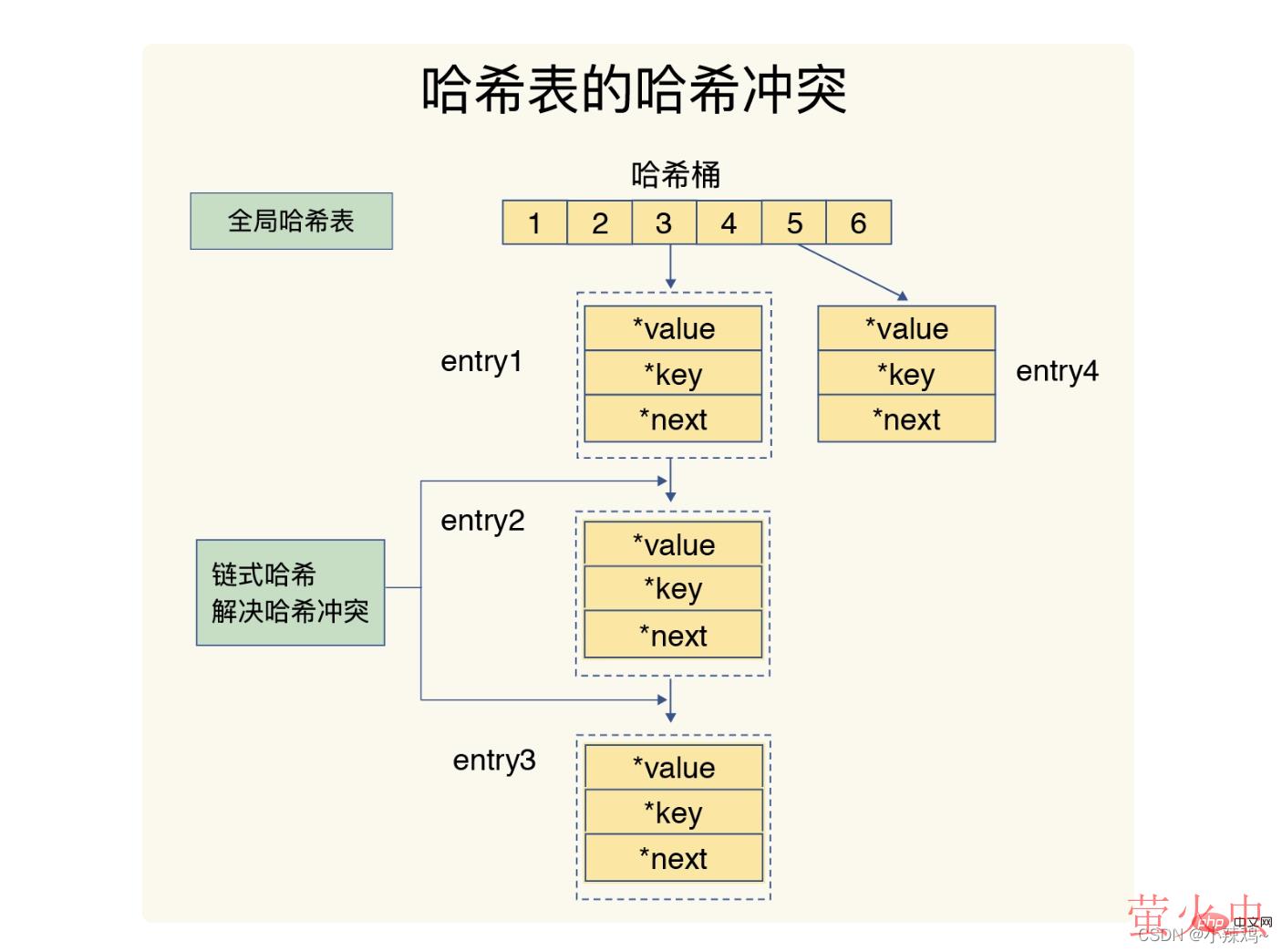
rehash的操作步骤:1.给哈希表分配更大的空间,例如是当前hash表大小的两倍
2.把哈希表1中的数据重新映射并拷贝到hash表2上
3.释放哈希表1的空间
第二步涉及大量数据拷贝操作,如果一次性把哈希表1中的数据都迁移完,会造成线程阻塞,无法服务其他请求。为了避免这一问题,redis采用渐进式rehash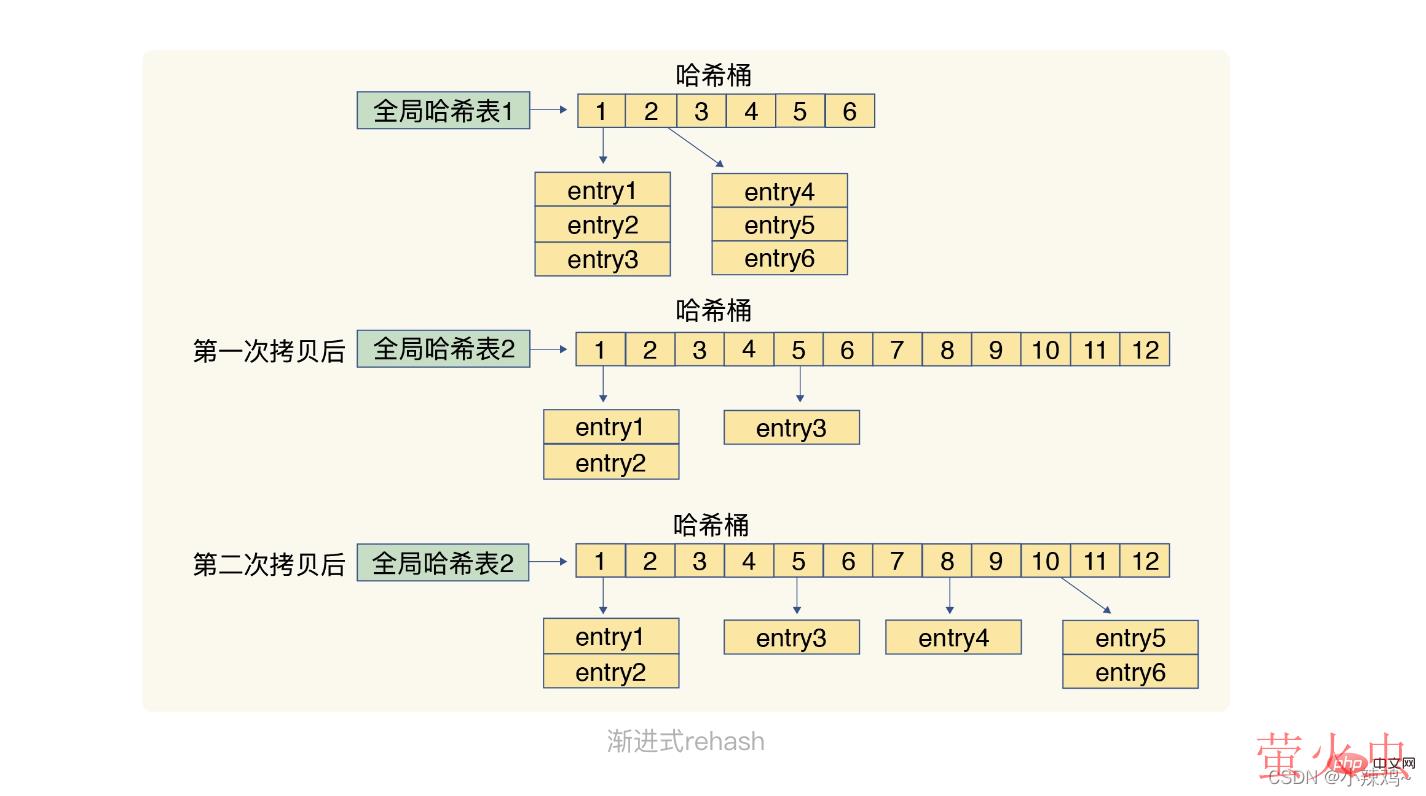
整数数组和双向链表的复杂度都是O(N)
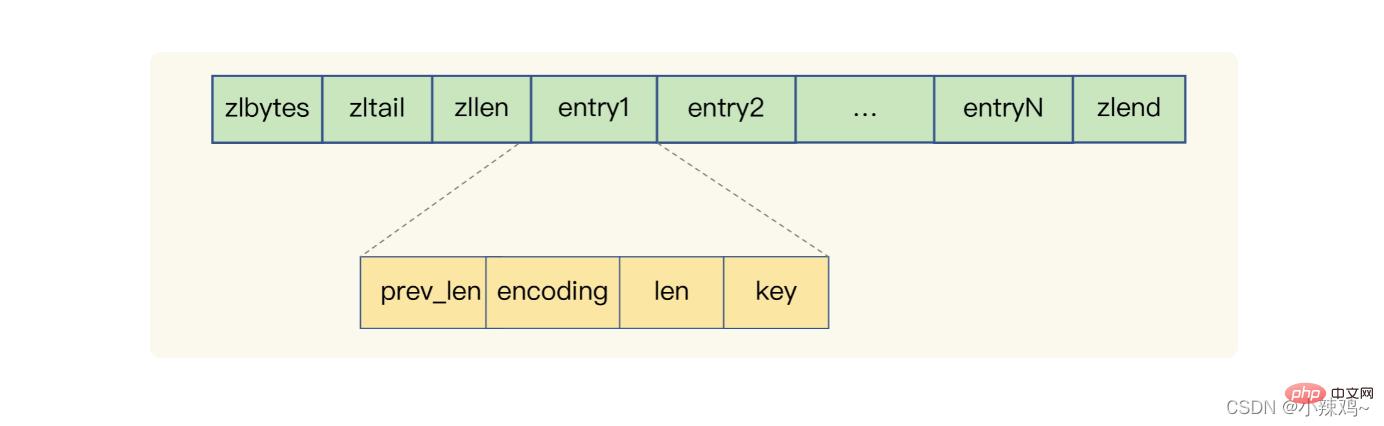
压缩列表在表头有三个数据分别是列表长度、列表尾的偏移量和列表中entry个数
压缩列表在表尾还有一个元素zlend代表列表结束
跳表:有序链表只能逐一查找元素,而跳表在链表的基础上增加了多级索引,通过索引位置的几次跳转实现数据的快速定位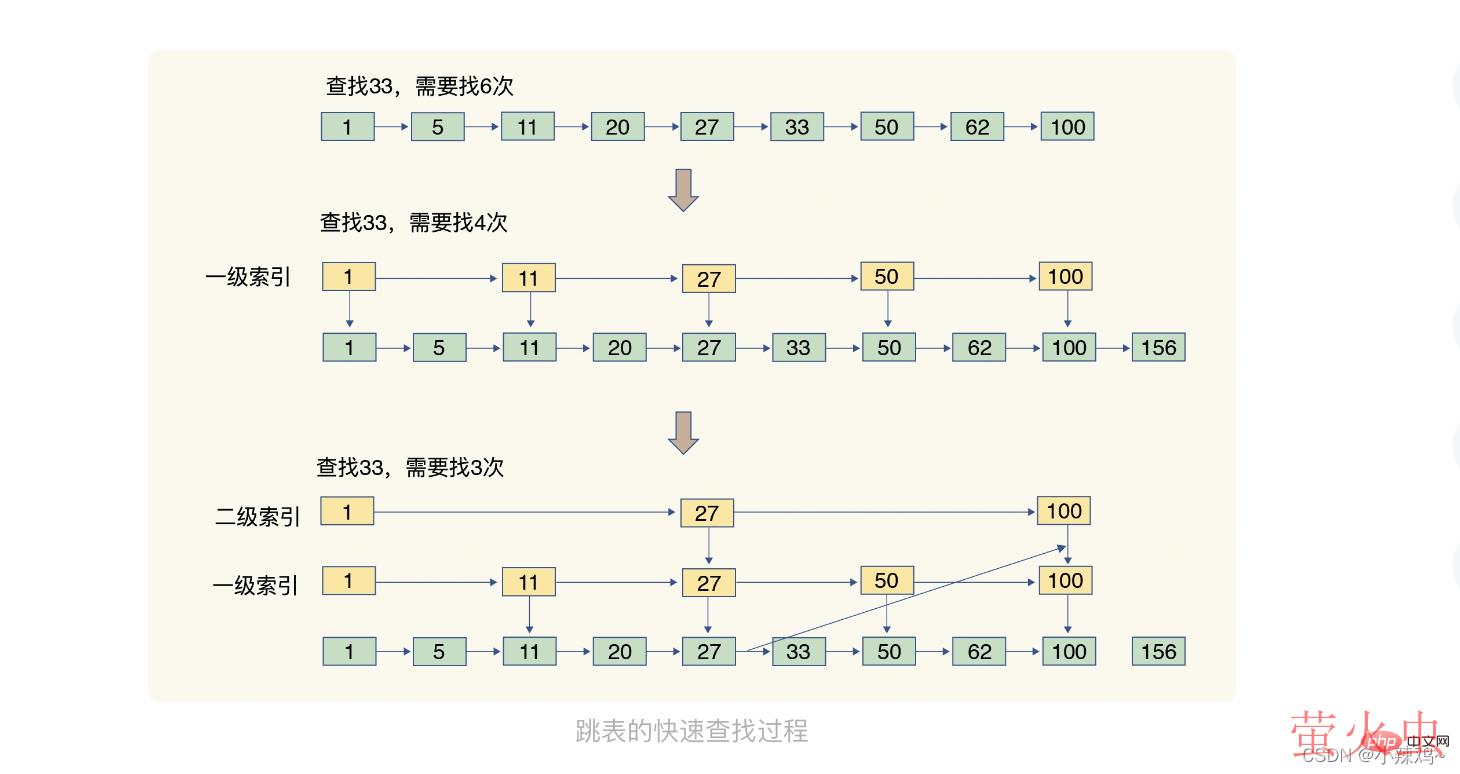
以下五种结构的时间复杂度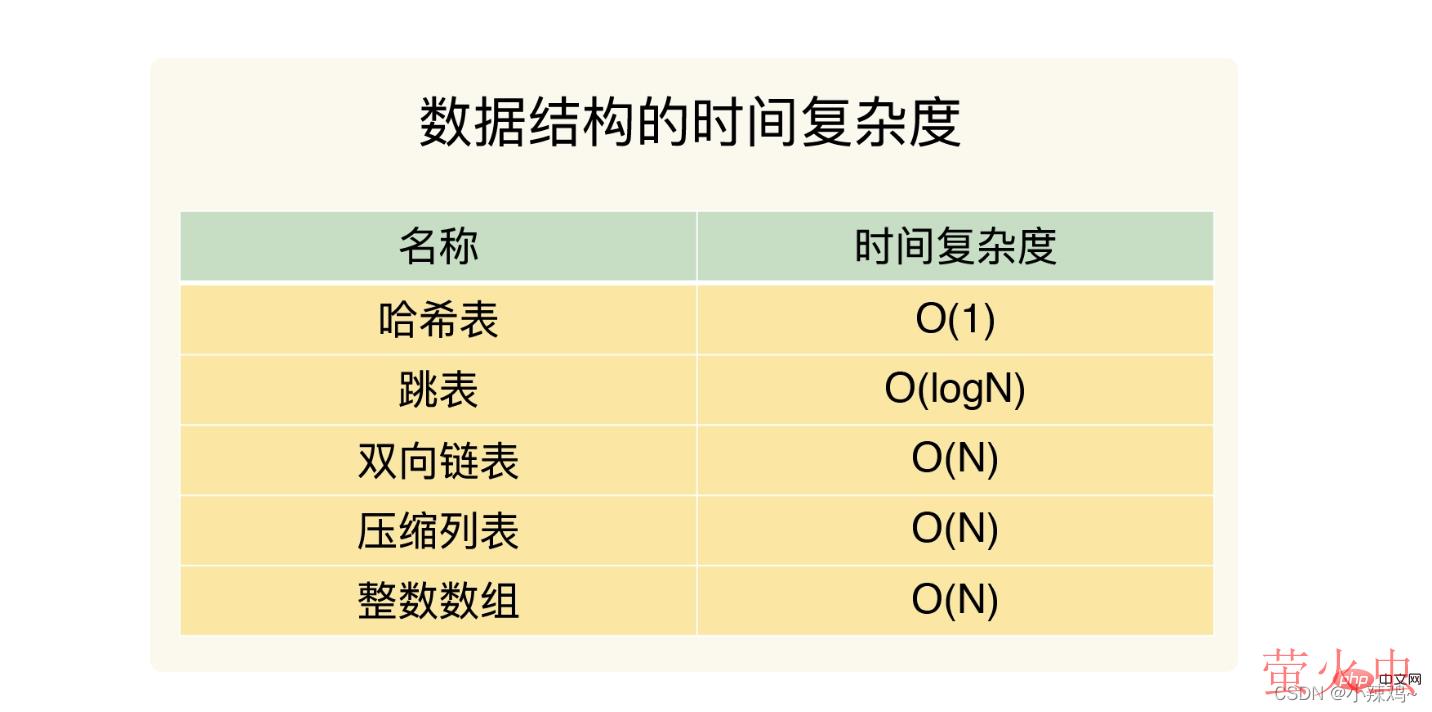
String类型
String类型并不适用于所有场景,它有一个明显的短板就是它在保存数据时所消耗的内存空间较多。因为String类型需要额外内存空间记录数据长度、空间使用等信息,这些信息也叫做元数据。
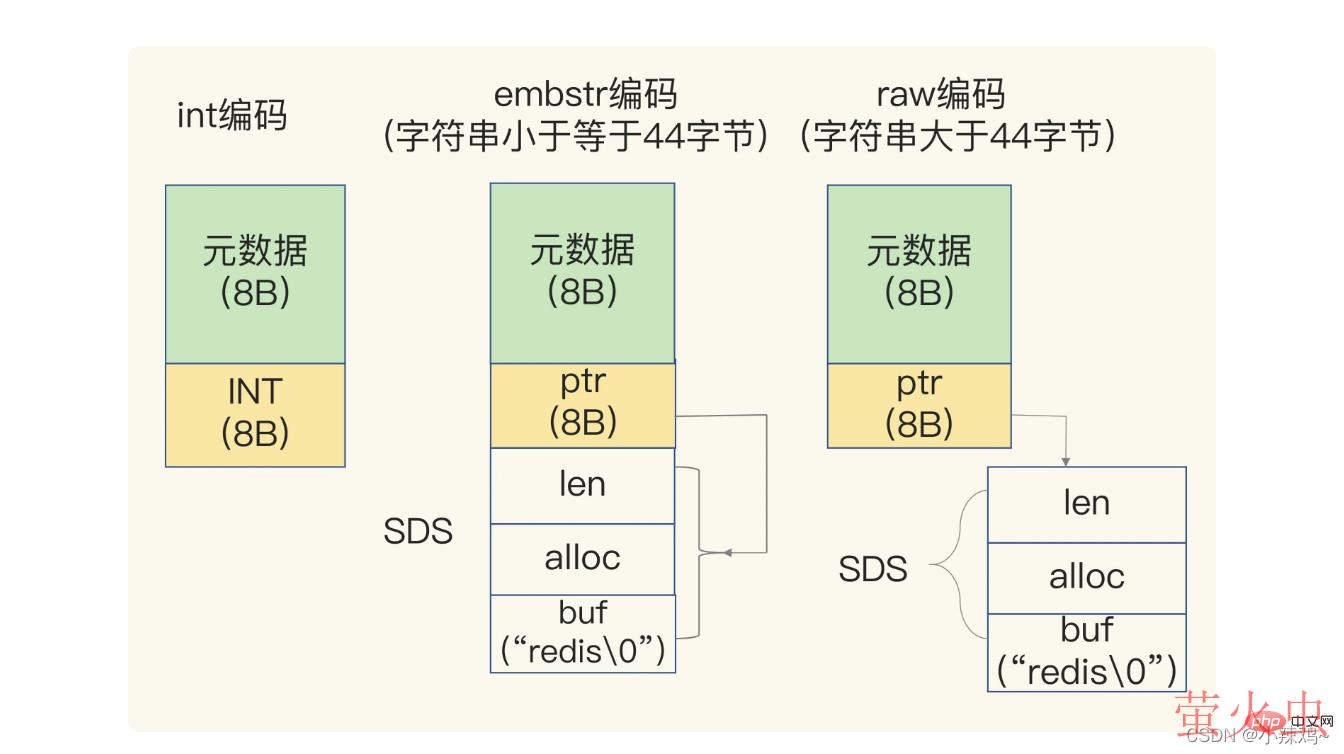
当保存的数据包含字符的时候,string会用简单动态字符串SDS结构体来保存
len是buf已用长度 alloc是buf实际分配长度
因为redis数据类型有很多,不同的数据类型有相同的元数据要记录,所以redis会用一个RedisObject结构体来统一记录这些元数据
当保存Long类型的时候,RedisObject的指针就直接赋值为整数数据了,这样就不用额外的指针再指向整数了,节省了指针的空间开销。
如果保存的字符串小于44字节,sds和元数据会被分配到一块连续的内存区域,被称为embstr编码
如果保存的字符串大于44字节,SDS和元数据会分开存放,被称为raw编码
另外redis会使用一个全局hash表保存所有键值对,hash表的每一项都是一个dictEntry的结构体,用来指向一个键值对,可以看到key+value+next会使用24字节,但是实际占用32字节,这是因为jemalloc 在分配内存时,会根据我们申请的字节数 N,找一个比 N 大,但是最接近 N 的 2 的幂次数作为分配的空间,这样可以减少频繁分配的次数。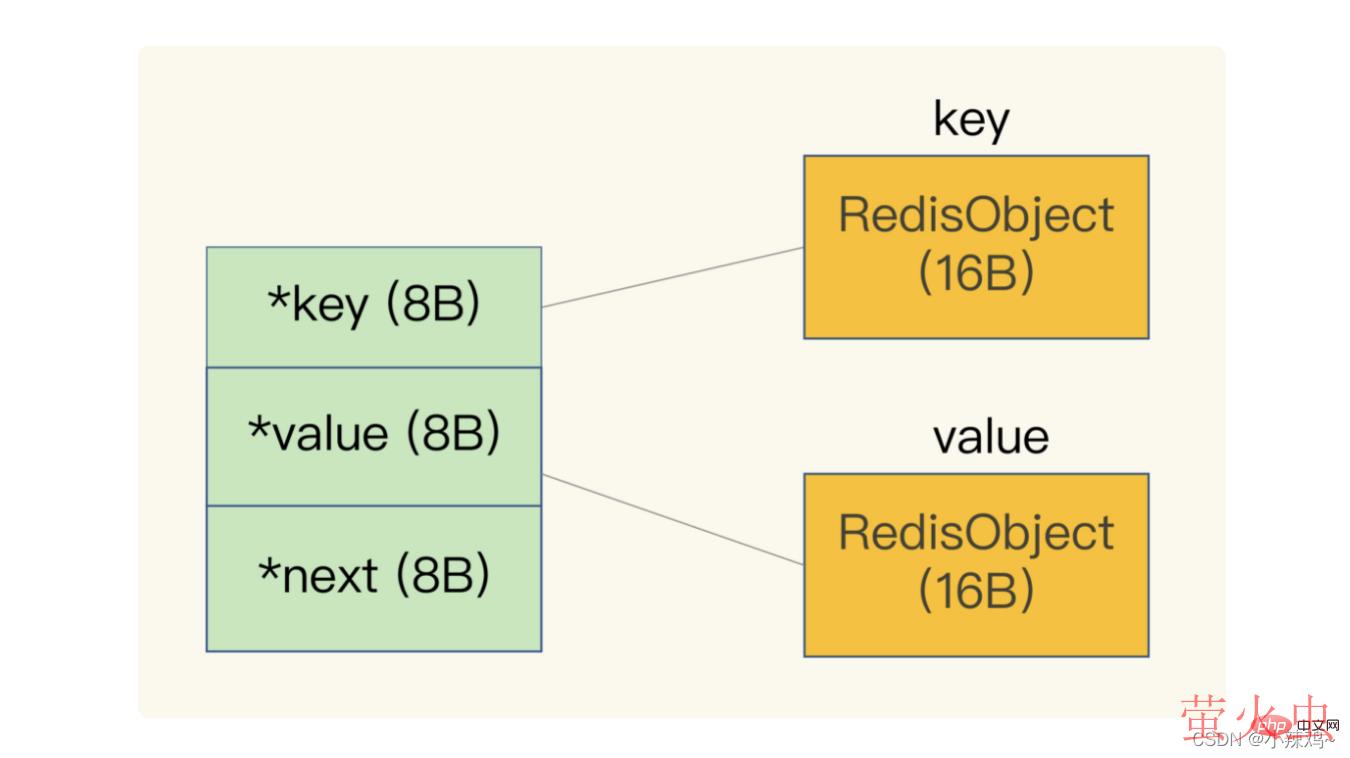
用什么数据结构可以节省内存呢?
压缩列表:zlbytes代表列表长度,zltail代表列表尾偏移量,zllen代表列表中的entry个数,zlend代表列表结束,perv_len代表前一个entry长度,encoding代表编码方式,len代表自身长度,key是实际存储的数据。redis基于压缩列表实现了list、hash和Sorted Set
如何用集合类型保存单值的键值对?
在保存单值的键值对的时候,可以采用Hash的二级编码,就是把单值的数值拆分成两部分,前一部分作为Hash的key,后一部分作为Hash的value
以图片 ID 1101000060 和图片存储对象 ID 3302000080 为例,我们可以把图片 ID 的前 7 位(1101000)作为 Hash 类型的键,把图片 ID 的最后 3 位(060)和图片存储对象 ID 分别作为 Hash 类型值中的 key 和 value。127.0.0.1:6379> info memory# Memoryused_memory:1039120127.0.0.1:6379> hset 1101000 060 3302000080(integer) 1127.0.0.1:6379> info memory# Memoryused_memory:1039136Hash类型有两种底层实现结构:1.压缩列表 2.Hash表
hash列表存在两个阀值,一旦超过这两个阀值就会从压缩列表转换为Hash表
hash-max-ziplist-entries表示用压缩列表保存时哈希列表集合中最大元素个数
hash-max-ziplist-value表示用压缩列表保存时哈希集合单个元素的最大长度
集合统计模式
1.聚合统计
2.排序统计
3.二值状态统计
4.基数统计
redis的三种扩展数据类型
1.Bitmap:
2.HyperLogLog
3.GEO:
面向LBS应用的GEO数据类型
GEO的底层结构是根据Sorted Set来实现的,Sorted Set可以根据元素的权重排序,支持范围查询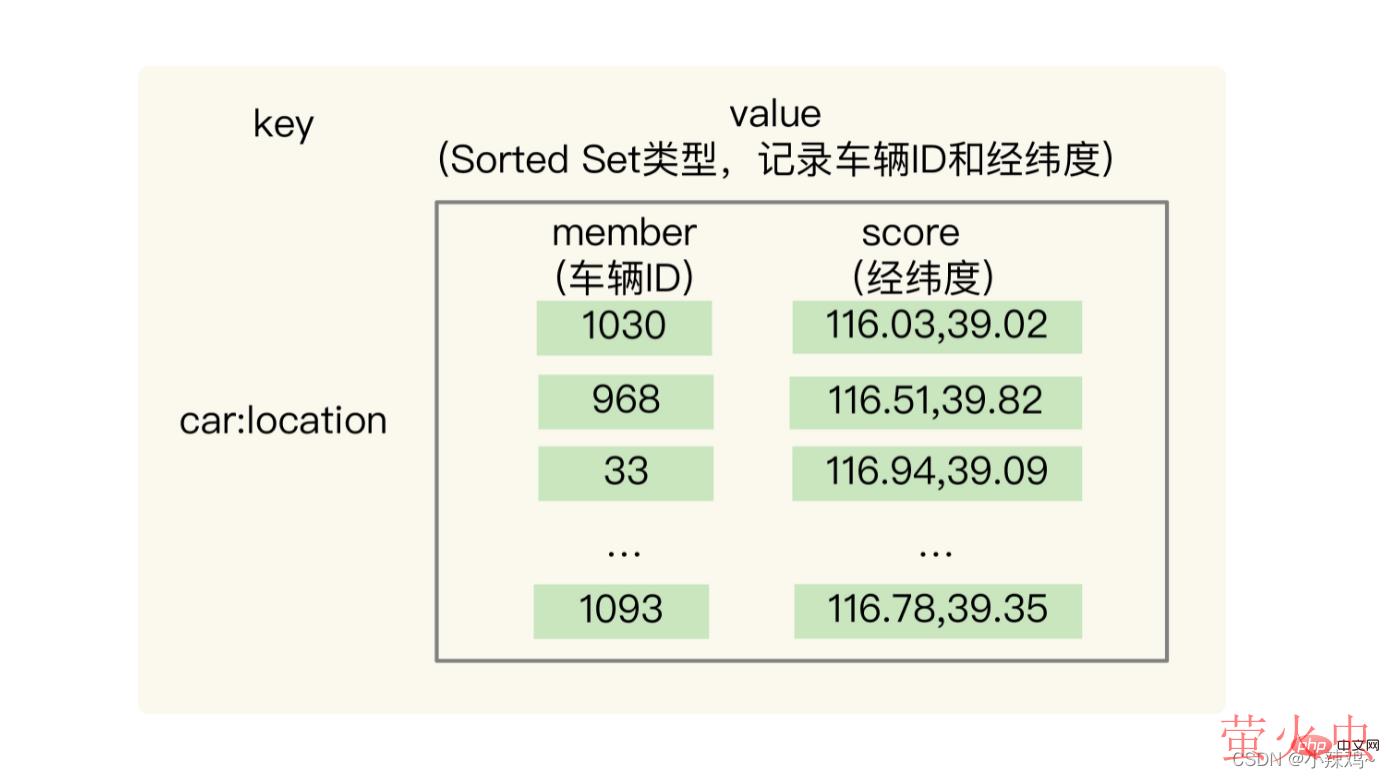
sorted Set的权重分数是一个浮点数(float类型),而经纬度是两个数,需要用GeoHash 编码
GeoHash编码是通过“二分区间,区间编码”的方式进行的。
先把经度和纬度换算成编码的格式,然后再进行交叉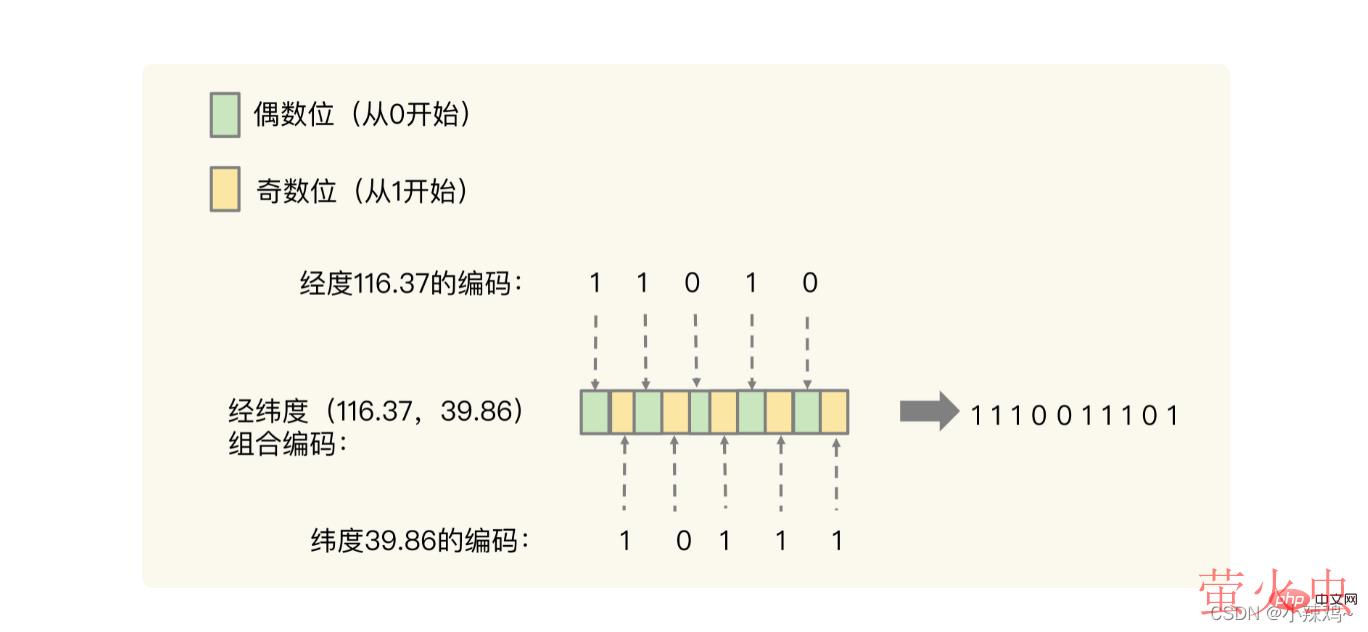
实际上交叉的目的是下图所示的概念,交叉后实际上就可以定位到二维空间上的一个方格中,我们使用 Sorted Set 范围查询得到的相近编码值,在实际的地理空间上,也是相邻的方格,例如1110011101和1111011101是空间位置相邻的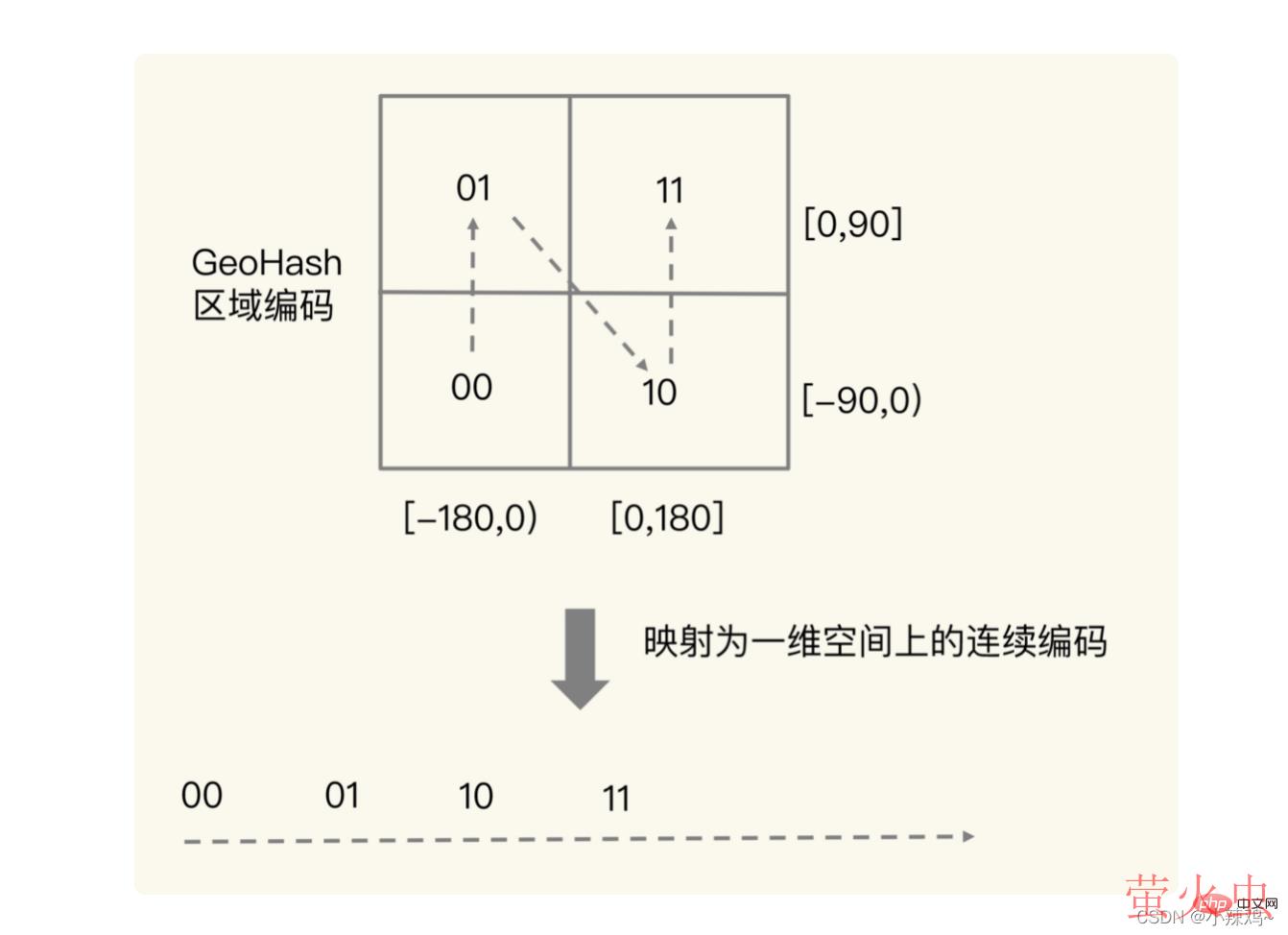
但是会存在编码相邻,但是方格实际不相邻的情况。所以为了避免这种情况发生我们可以同时查询给定经纬度周围4个或者8个方格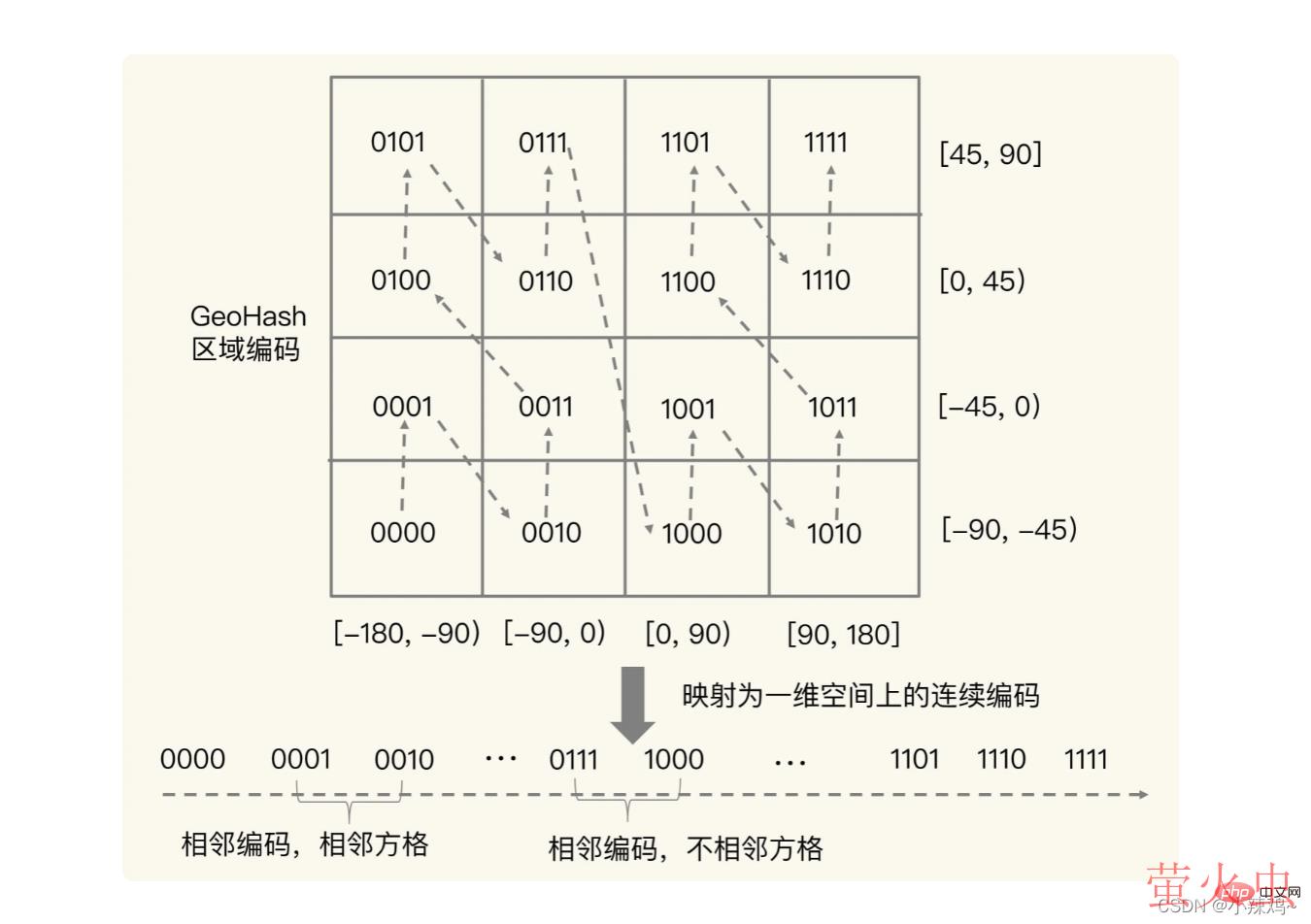
如何操作GEO类型?
在使用GEO类型时,我们经常使用到的两个命令分别时GEOADD和GEORADIUS
GEOADD:用于把一组经纬度信息和相对应的一个ID记录到GEO类型集合中。
使用方法:假设车辆ID是33,经纬度位置是(116.034579,39.030452),我们可以用一个 GEO 集合保存所有车辆的经纬度,集合 key 是 cars:locations。只需要执行以下命令就可以把ID号为33的车辆的当前经纬度位置存入到GEO中。
GEOADD cars:locations 116.034579 39.030452 33GEORADIUS:根据输入经纬度的位置,查询以这个经纬度为中心一定范围内的其他元素
如何自定义数据类型?
redis的基本对象结构包含type、encoding、lru和refcount、*ptr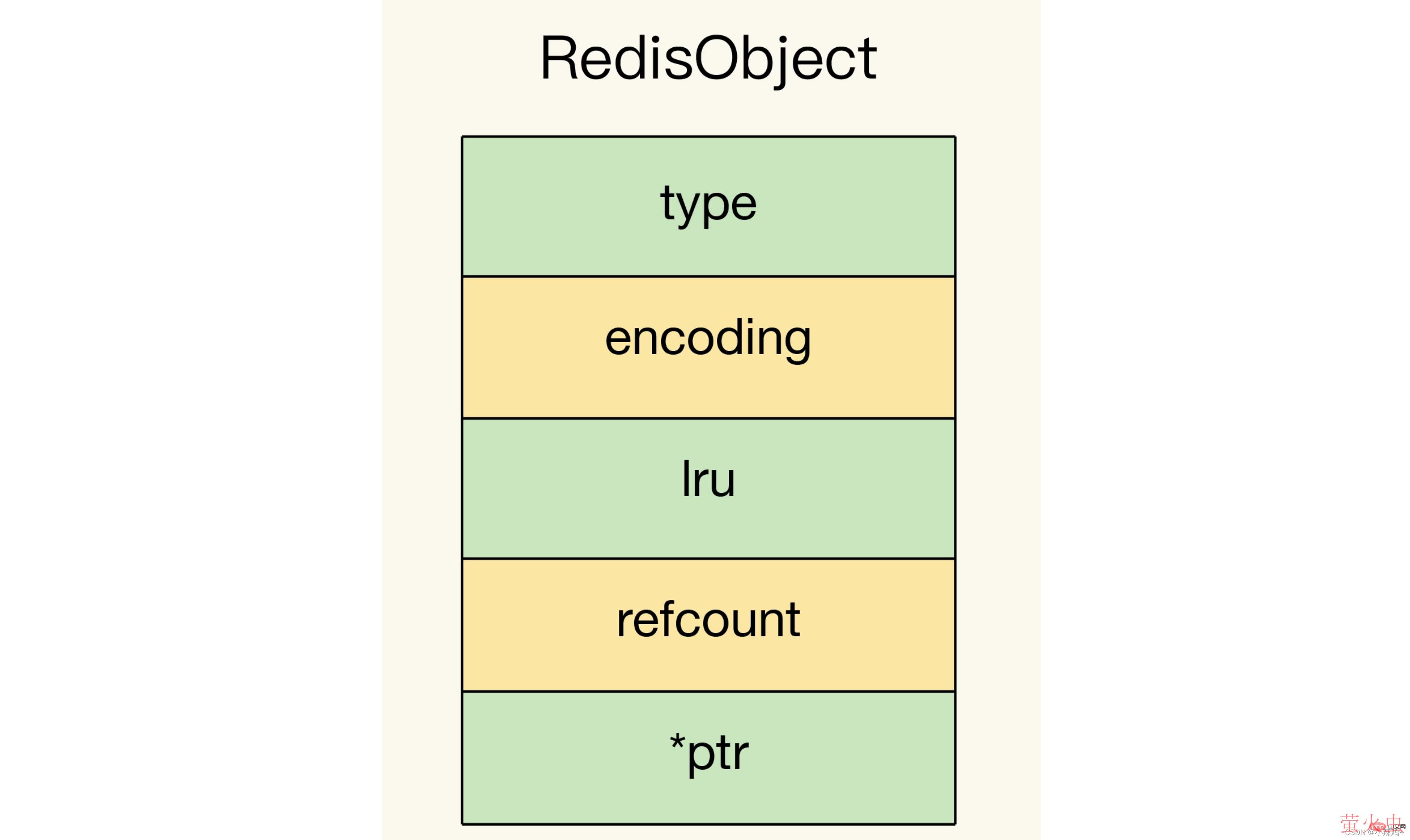
开发一个名字叫NewTypeObject的数据结构,具体有以下四个步骤
如何在redis中保存时间序列数据?
1.基于Hash和Sorted Set保存:为什么要基于两种数据结构进行查询呢?
Hash类型可以实现单键的快速查询,这就满足了时间序列单键查询需求
但是hash类型有一个短板就是不支持范围查询,为了支持时间戳范围查询我们需要通过Sorted Set,因为它根据元素的权重分数来排序的,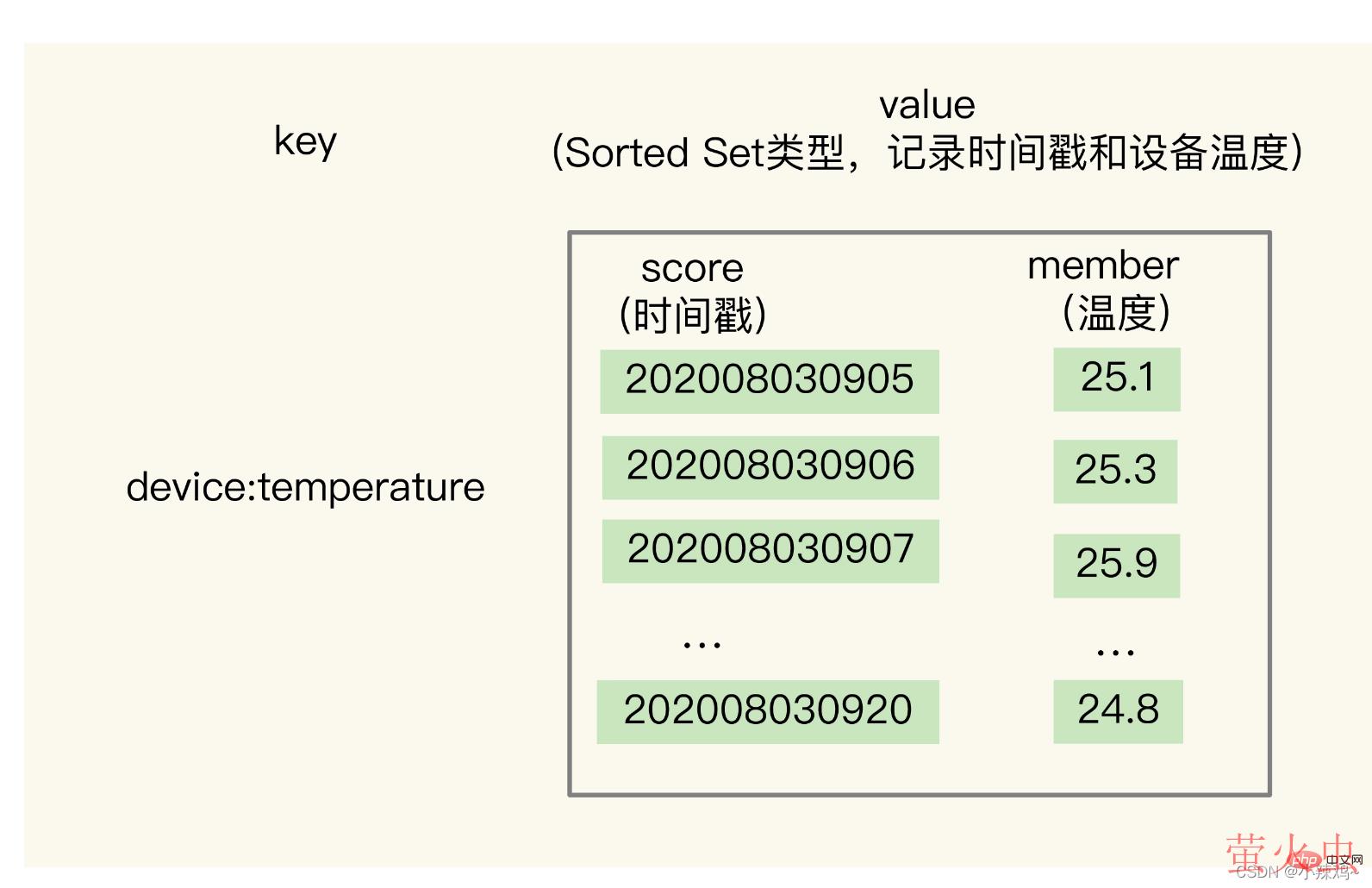
那么我们怎么保证这两个操作的原子性呢?
需要通过MULTI和EXEC两个命令:
MULTI表示开始,收到这个命令redis就会将命令放入到队列中
EXEC表示结束,收到这个命令就会开始执行队列中的命令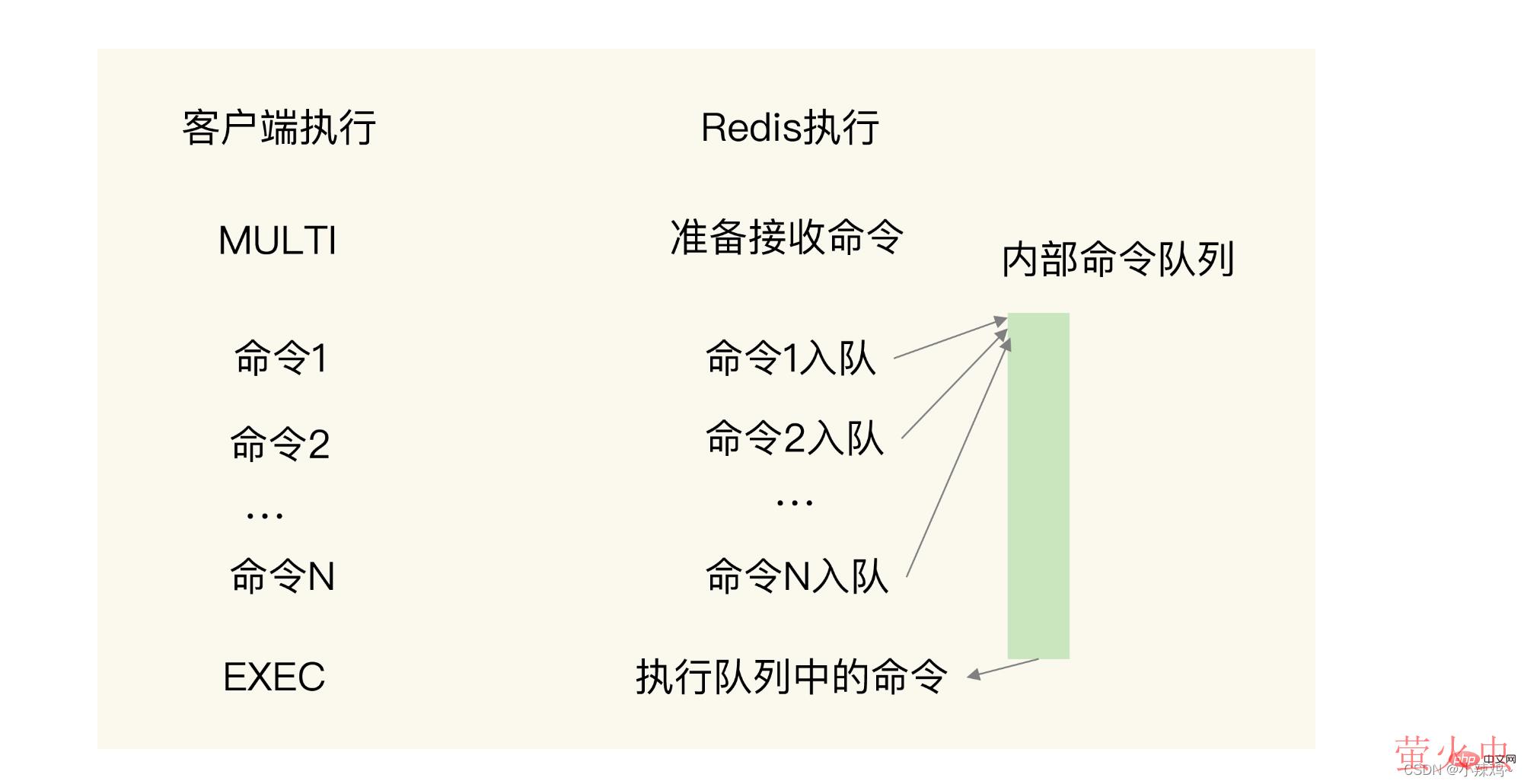
但是如果采用hash和Sorted Set则只支持范围查询而不支持聚合计算。如果在客户端做聚合计算,会导致大量的网络传输。所以可以在redis上通过RedisTimeSeries进行聚合计算。
以上就是redis数据结构知识图文详解的详细内容,转载自php中文网


发表评论 取消回复