
什么是BigKey?
BigKey指的是redis中一些key value值很大,这些key在序列化与反序列化过程中花费的时间很大! 操作bigkey的通常比较耗时,也就意味着阻塞Redis可能性越大!占用的流量同时也会变得很大!
大白话就是bigkey实际指一个key对应的value很大,占用的空间很大!
string长度大于10K,list长度大于10240认为是big bigkeys
如何查看Redis中的bigKey?
我们以String为例:
先存储几个String key进去,然后使用命令!
查看所有BigKey
redis-cli自带的一个命令(不需要连接Redis)。对整个redis进行扫描,寻找较大的key。
redis-cli -h 127.0.0.1 -p 6379 --bigkeys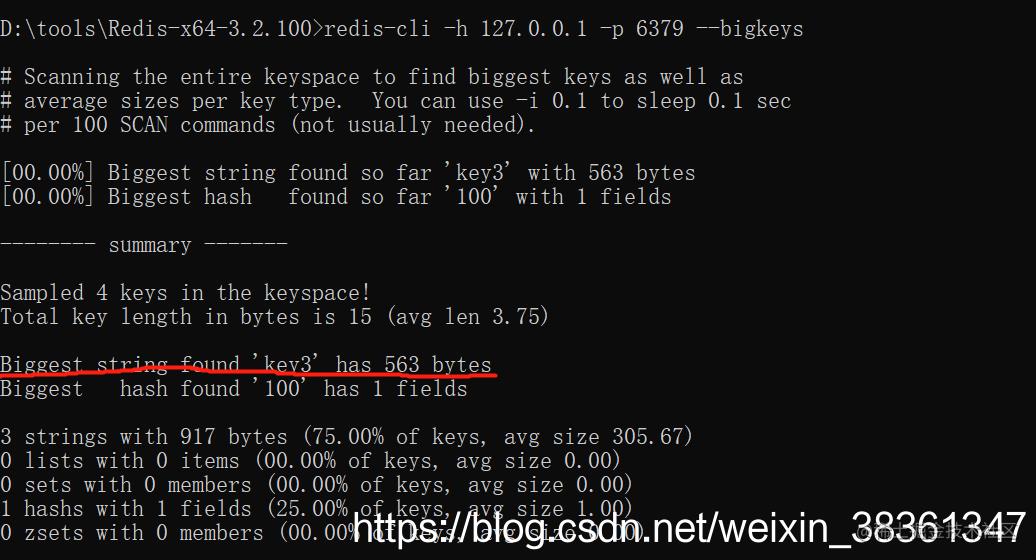
Redis中有3个String , 可以看到发现一个BigKey key3
获取key3的值 看看
该命令使用scan方式对key进行统计,所以使用时无需担心对redis造成阻塞。
输出大概分为两部分,summary之上的部分,只是显示了扫描的过程。
- summary部分给出了每种数据结构中最大的Key。
- 统计出的最大key只有string类型是以字节长度为衡量标准的。
- list,set,zset等都是以元素个数作为衡量标准,不能说明其占的内存就一定多。所以,
如果你的Key主要以string类型存在,这种方法就比较适合。
我的hash中

key3值

这种是查看所有的key 是否是bigKey
查看单个Key
debug object

其中serializedlength表示key对应的value序列化之后的字节数
注意:
debug object bigkey本身可能就会比较慢,它本身就会存在阻塞Redis的可能,可能会比较危险、而且不太准确(序列化后的长度);
memory usage
Redis 4.0开始提供memory usage命令可以计算每个键值的字节数
如何优化
优化big key的原则就是string减少字符串长度,list、hash、set、zset等减少成员数;
string长度大于10K,list长度大于10240认为是big bigkeys
1 拆分
如果对象是整存争取
将对象拆分后才能多个小key-value,get不同的key或者批量获取stringRedisTemplate.opsForValue() .multiGet(keyList)如果对象是部分更新获取数据
可以分拆成几个key-value,也可以存储在hash中,部分更新部分存取!
如果是hash ,set,zset ,list 等元素
固定一个桶的数量,比如1000,每次存取的时候,先在本地计算field的hash值,模除1000,确定该field落在哪个key上。
newHashKey = hashKey + (hash(field) % 1000);
hset(newHashKey, field, value);
hget(newHashKey, field)
set, zset, list 也可以类似上述做法!
2 本地缓存
减少访问redis次数,降低危害减少访问redis次数,降低危害! 当然本地开销也会变大!
到此这篇关于Redis BigKey的问题解决的文章就介绍到这了,更多相关Redis BigKey内容请搜索萤火虫技术以前的文章或继续浏览下面的相关文章希望大家以后多多支持萤火虫技术!



发表评论 取消回复