
为什么需要 SkipList(跳表)
在普通链表中查找元素的时候,因为需要遍历查找,所以查询效率非常低,时间复杂度是O(N)。
因此我们需要跳表。跳表是在链表基础上改进过来的,实现了一种 “多层” 的 有序 链表,这样的好处是能快速定位数据。
跳表的结构设计
如下图所示,这是一个层级为3的跳表
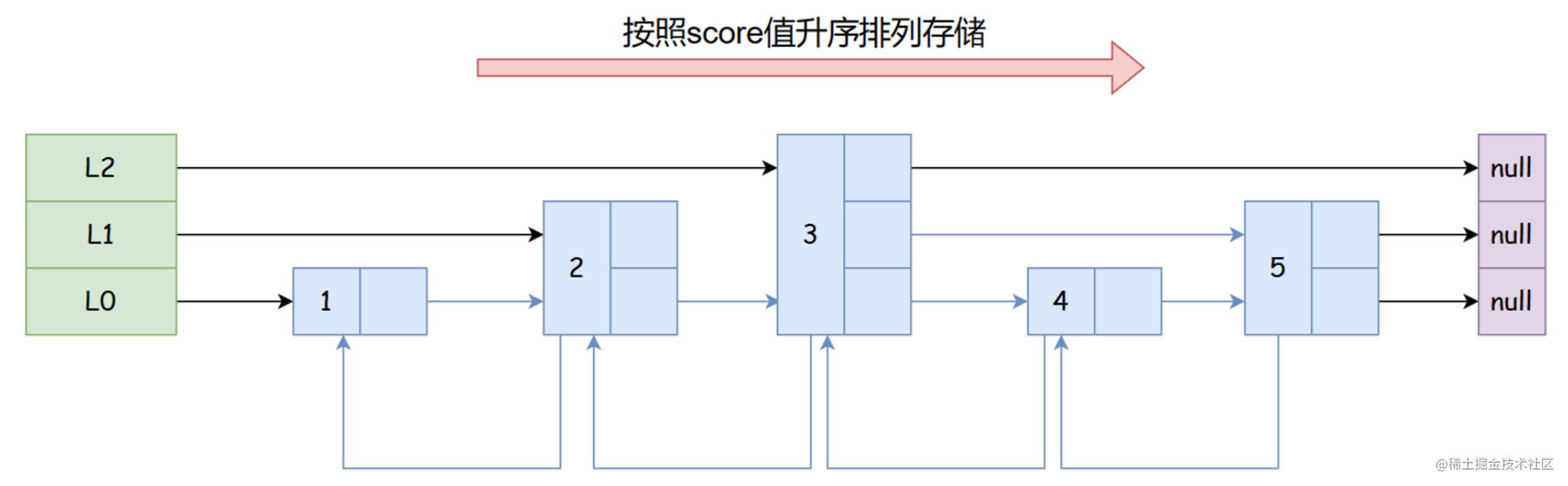
和普通的双向链表一样,SkipList 都有一个指向上一个节点的指针,也有一个指向下一个节点的指针。
但是你会发现,在层次为 3 的跳表中,会有三级指针的存在,而且 SkipList 中元素会按照 score 值升序排序(score 值一样则按照 ele 排序)
- 一级指针普通链表一样,指向下一个节点(图中的 L0)
- 二级指针跨度为2,指向的节点与自己间隔了一个节点
- 三级指针跨度为3,指向的节点与自己间隔了两个节点
这样的设计会带来什么好处呢?
- 假设我们要在普通链表中查询值为 3 的节点,我们需要从头结点开始,向后遍历1 → 2 → 3 ,三个节点才能找到。时间复杂度为 O(n)
- 当使用了 SkipList 这个数据结构之后,我们可以直接通过三级指针(L2),直接找到这个节点(建立在元素有序的情况下,类似于二分查找一步一步缩小范围)。时间复杂度为 O(logN)
跳表的节点(zskiplistNode )
我们来看看跳表的结构体源码
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;其中,
- ele,用于存储该节点的元素
- score,用于存储节点的分数(节点按照 score 值排序,score 值一样则按照 ele 排序)
- *backward,指向上一个节点
而 level[] 就是实现跳表多层次指针的关键所在,level 数组中的每一个元素代表跳表的一层,比如 leve[0] 就表示第一层,leve[1] 就表示第二层。zskiplistLevel 结构体里定义了指向下一个跳表节点的指针** *forward 和用来记录两个节点之间的距离 span,如图所示,
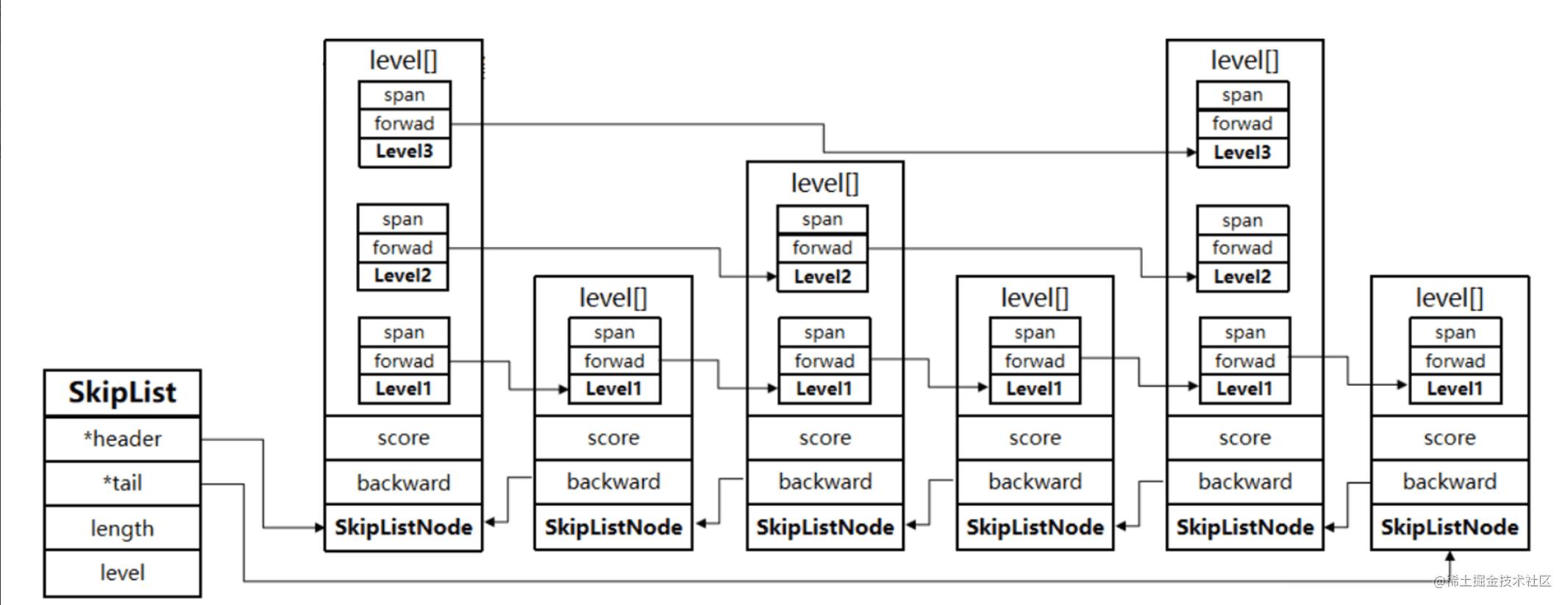
???? span 跨度有什么用?
- 第一眼看到跨度的时候,你可能以为是遍历操作有关,实际上并没有任何关系,遍历操作只需要用前向指针(
struct zskiplistNode *forward)就可以完成了。 - 跨度实际上是为了计算这个节点在跳表中的位置。具体怎么做的呢?
- 因为跳表中的节点都是按序排列的,那么计算某个节点位置的时候,从头节点点到该结点的查询路径上,将沿途访问过的所有层的跨度累加起来,得到的结果就是目标节点在跳表中的排位。
- 举个例子,查找图中节点 3 在跳表中的排位,从头节点开始查找节点 3,查找的过程只经过了一个层(L2),并且层的跨度是 3,所有节点 3 在跳表中的排位是 3。
跳表(zskiplist )
跳表的结构如下
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;- zskiplistNode *header, *tail ,跳表的头尾节点
- length,跳表的长度
- level,跳表的最大层数
跳表的查询过程
在使用 ZRANGEBYSCORE key min max进行范围查询的时候
- redis 会调用
zslFirstInRange或zslLastInRange函数获取符合范围条件的起始节点(正序调用**zslFirstInRange** ,逆序调用**zslLastInRange** ) - 获取起始节点之后,进入一个循环,每次迭代时都会检查节点的分数是否仍在范围内(如果存在偏移量,跳过指定数量的元素,而不进行分数的检查),如果不在范围内,则中止循环。
- 这样就能获取指定分数内的所有元素。
可在 t_zset.c#genericZrangebyscoreCommand(zrange_result_handler *handler, zrangespec *range, robj *zobj, long offset, long limit, int reverse) 查看源码
在 zslFirstInRange (zslLastInRange 类似)中,我们就能看到跳表根据 scroe 值的查询过程,源码如下:
/* Find the first node that is contained in the specified range.
* Returns NULL when no element is contained in the range. */
zskiplistNode *zslFirstInRange(zskiplist *zsl, zrangespec *range) {
zskiplistNode *x;
int i;
/* If everything is out of range, return early. */
if (!zslIsInRange(zsl,range)) return NULL;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* Go forward while *OUT* of range. */
while (x->level[i].forward &&
!zslValueGteMin(x->level[i].forward->score,range))
x = x->level[i].forward;
}
/* This is an inner range, so the next node cannot be NULL. */
x = x->level[0].forward;
serverAssert(x != NULL);
/* Check if score <= max. */
if (!zslValueLteMax(x->score,range)) return NULL;
return x;
}该函数执行逻辑如下:
- 首先,通过调用
zslIsInRange函数检查整个有序集合是否都在范围之外,如果是,则直接返回空,表示范围内不存在满足条件的节点。 - 初始化变量
x为跳表的头节点。 - 从跳表的最高层级开始逆序遍历每个层级,直到达到最底层级。
- 在每个层级中,通过比较节点的分数(score)和范围的最小值,向前遍历跳表,直到找到第一个在范围内的节点。
- 最终,变量
x存储的是范围内第一个节点的前一个节点。 - 使用
serverAssert函数进行断言,确保变量x的下一个节点不为空(如果跳表中存在节点,则下一个节点不应为空)。 - 更新变量
x为下一个节点,即范围内的第一个满足条件的节点。 - 检查变量
x的score 是否小于等于范围的最大值,如果大于最大值,则返回空,表示范围内不存在满足条件的节点。 - 返回变量
x,即范围内的第一个满足条件的节点。
简单来说在 SkipList 中找到一个元素的步骤如下:
- 从跳表的顶层开始,从左到右遍历指针,直到找到一个指针指向的值大于或等于目标元素。记录下该位置作为当前位置。
- 如果当前位置指向的值等于目标元素,则找到了目标元素,搜索结束。
- 如果当前位置的下一个指针存在且指向的值小于目标元素,将当前位置向右移动到下一个指针所指向的位置。重复步骤1。
- 如果当前位置的下一个指针不存在或指向的值大于目标元素,将当前位置向下移动一层。重复步骤1。
到此这篇关于Redis底层数据结构SkipList的实现的文章就介绍到这了,更多相关Redis SkipList内容请搜索萤火虫技术以前的文章或继续浏览下面的相关文章希望大家以后多多支持萤火虫技术!



发表评论 取消回复